Scalable Reinforcement Learning in Multi-Agent Environments
Tamás Takács1,Gergely Magyar1,&László Gulyás2
1MSc Students @ ELTE, Department of Artificial Intelligence
2Associate Professor @ ELTE, Department of Artificial Intelligence
Abstract
Novel reinforcement learning algorithms often face scalability and compatibility issues in multi-agent environments due to their optimization for single-agent settings. The lack of standardized methods for adaptation restricts their broader applicability, especially when dealing with rapidly changing numbers of controllable entities and massive scaling. Challenges include credit assignment, extensive memory usage, and increased computational time, leading to slow, destabilized training and suboptimal resource utilization. We propose a hybrid architecture, combining monolithic and distributed approaches, resulting in a 30-times reduction in model size and learning basic skills 24 times faster with 600-times fewer training examples compared to related works in the same environment. We also introduce trajectory separation, achieving a 3-times speed increase in training convergence. Our M-PPO-based hybrid model achieves:
- a performance-based environment
- separated agent trajectories
- separated reward, advantage, probability and entropy calculation
- reinforced positive behavior in early training
Introduction
A MARL solution can be conceptualized along a spectrum of organizational paradigms [[Piccoli 2023]]. At one end of the spectrum, the single-brain approach centralizes decision-making, where a collective of agents is treated as a single entity. In this model, a global observation is used to generate a unified trajectory, and rewards are distributed based on collective outcomes, which can inadvertently reinforce negative behaviors. In contrast, a hybrid model utilizes local information from all agents to generate a single trajectory but incorporates a global reward system.
Our research improves on this hybrid model by allocating rewards to individual agents or groups based on their specific contributions, thus creating a performance-based environment that operates at the individual or small group level. This approach involves dividing the environment’s trajectories among agents or groups, allowing for the calculation of rewards, log probabilities, value estimates, advantages, and entropy for each unit or group. This method bootstraps the learning process by ensuring that rewards only reinforce positive behaviors early on. At the other end of the spectrum is the fully multi-agent approach, where each entity interacting with the environment is treated as an independent learning agent. This significantly complicates the learning process by creating trajectories of varied lengths, as entities may enter or exit the scene, or be destroyed. Consequently, gathering a consistent amount of experience for each entity becomes challenging, especially when some entities may only exist in the environment for a fraction of the time compared to others. This situation leads to computational inefficiencies and data sparsity. Our solution effectively addresses these challenges by offering a framework that mitigates the issues associated with both the single-brain and fully multi-agent approaches. Our research also focuses on evaluating these methodologies in dynamically changing environments and offers insights into addressing computational and emergent intelligence challenges without heavy reliance on domain-specific constraints or rigid rules.
Environment
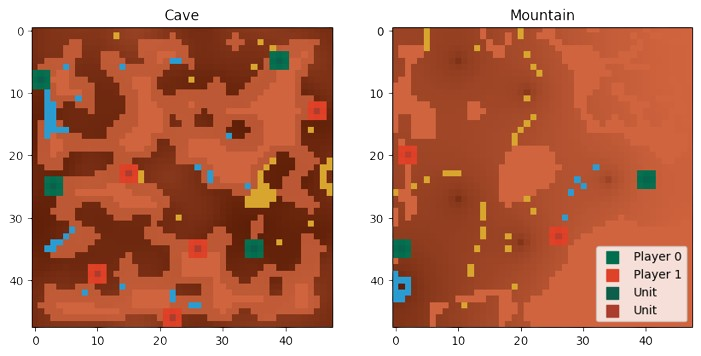
The Lux AI Environment represents a 2D grid platform tailored for Multi-Agent Reinforcement Learning (MARL) research [[Chen et al. 2023]], designed to tackle challenges in multi-variable optimization, resource acquisition, and allocation within a competitive 1v1 setting. Beyond optimization, proficient agents are tasked with adeptly analyzing their adversaries and formulating strategic policies to gain a decisive advantage. The environment is fully observed by all agents. For further information on the environment, visit the official competition documentation [[Tao, Pan, et al. 2023a]]. Figure 1 shows a visual representation of the grid environment, and Figure 2 illustrates the simplified environment loop.
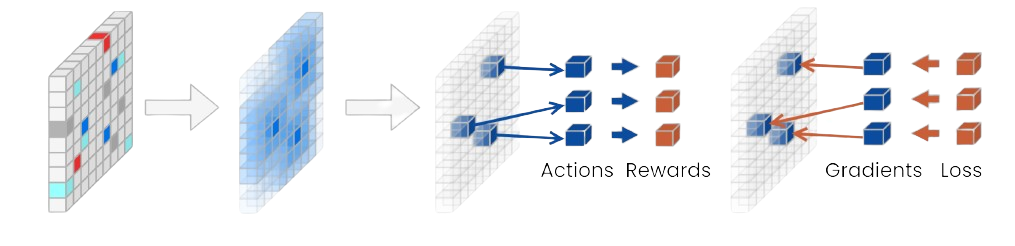
What is Trajectory Separation?
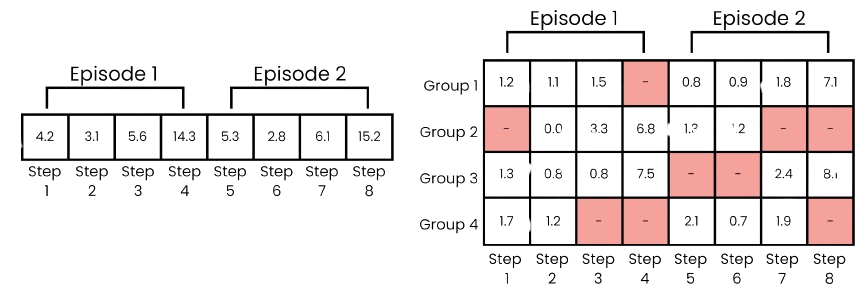
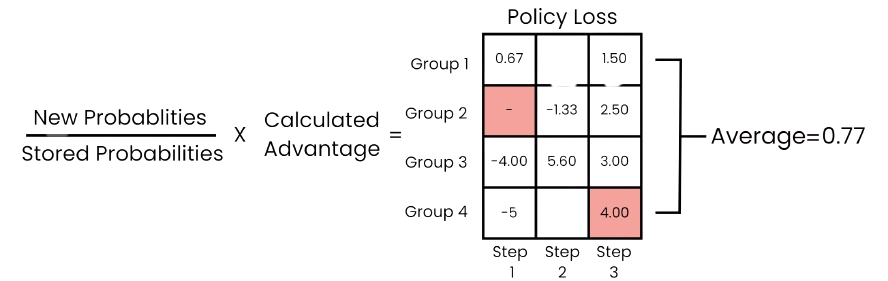
Trajectory separation is a technique used to improve credit assignment in multi-agent environments by tracking rewards, critic values, actions, and entropies separately for each entity or group of entities. Instead of aggregating rewards into a single global value, it breaks down each environment step into multiple distinct training examples. This approach allows for more precise attribution of rewards to specific actions, reducing the risk of skewed reward attribution that can occur when dealing with many entities. As a result, it enhances the accuracy of backpropagation, reinforcing beneficial behaviors and correcting detrimental ones more effectively. The difference between global and separated rewards is illustrated in Figure 3 , and Figure 4 demonstrates the policy loss calculation with the extended dimension.
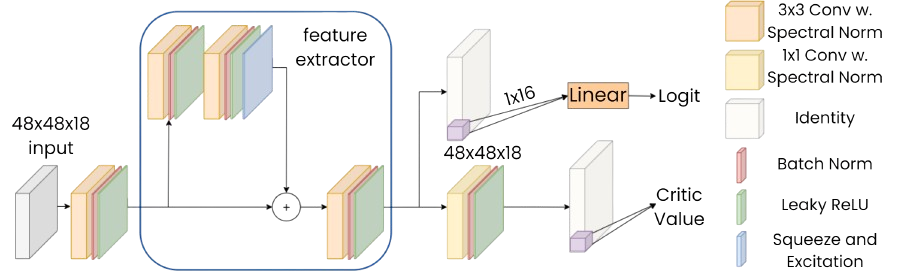
Global Feature Extractor
We developed a global feature extractor to learn a comprehensive mapping from environmental states to actions. This approach allows us to capture a unified behavior pattern, enhanced by the individual actions of agents, thereby achieving emergent collaborative intelligence. The architecture is shown in Figure 5 , and our novel backpropagation approach using trajectory separation is detailed in Figure 6 .
Results
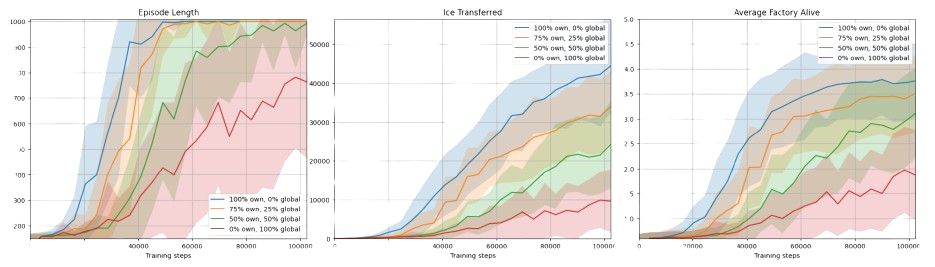
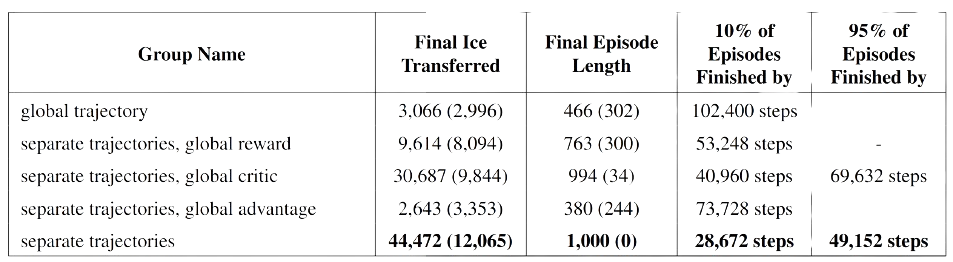
In our study, we compared our results with other competition submissions, conducted experiments on various credit assignment setups, and performed ablation studies. The effectiveness of trajectory separation is demonstrated in Figure 7 , and a detailed comparison of separated components is presented in Figure 8 .
Conference Presentation
I had the opportunity to present this work at the Magyar Machine Learning Találkozó (Hungarian Machine Learning Conference), a three-day event in Budapest ( Figure 9 ).

Citation
Read the full paper for more details: [[Paper]], and if you find this work informative please consider citing it:
@article{tamastheactual,
soon...
}