Failure Modes of Zero-Shot Machine Unlearning in Reinforcement Learning and Robotics
Tamás Takács1 & László Gulyás2
1PhD Student @ ELTE, Department of Artificial Intelligence
2Associate Professor @ ELTE, Department of Artificial Intelligence
Abstract
Machine unlearning, the targeted removal of data influence from trained models, is becoming increasingly important as intelligent robotic systems operate in dynamic environments and must comply with evolving privacy regulations, such as the General Data Protection Regulation (GDPR) and its “right to be forgotten” provision.
Zero-shot unlearning has emerged as a promising approach, enabling robots and reinforcement learning (RL) agents to forget specific data or classes without retaining the original training data. This ability is essential for flexible deployment and long-term adaptation.
In this work, we highlight a key limitation of current zero-shot unlearning frameworks. We find that forget-set accuracy, after initially dropping, can unexpectedly recover during continued training. This suggests that forgotten information may gradually resurface.
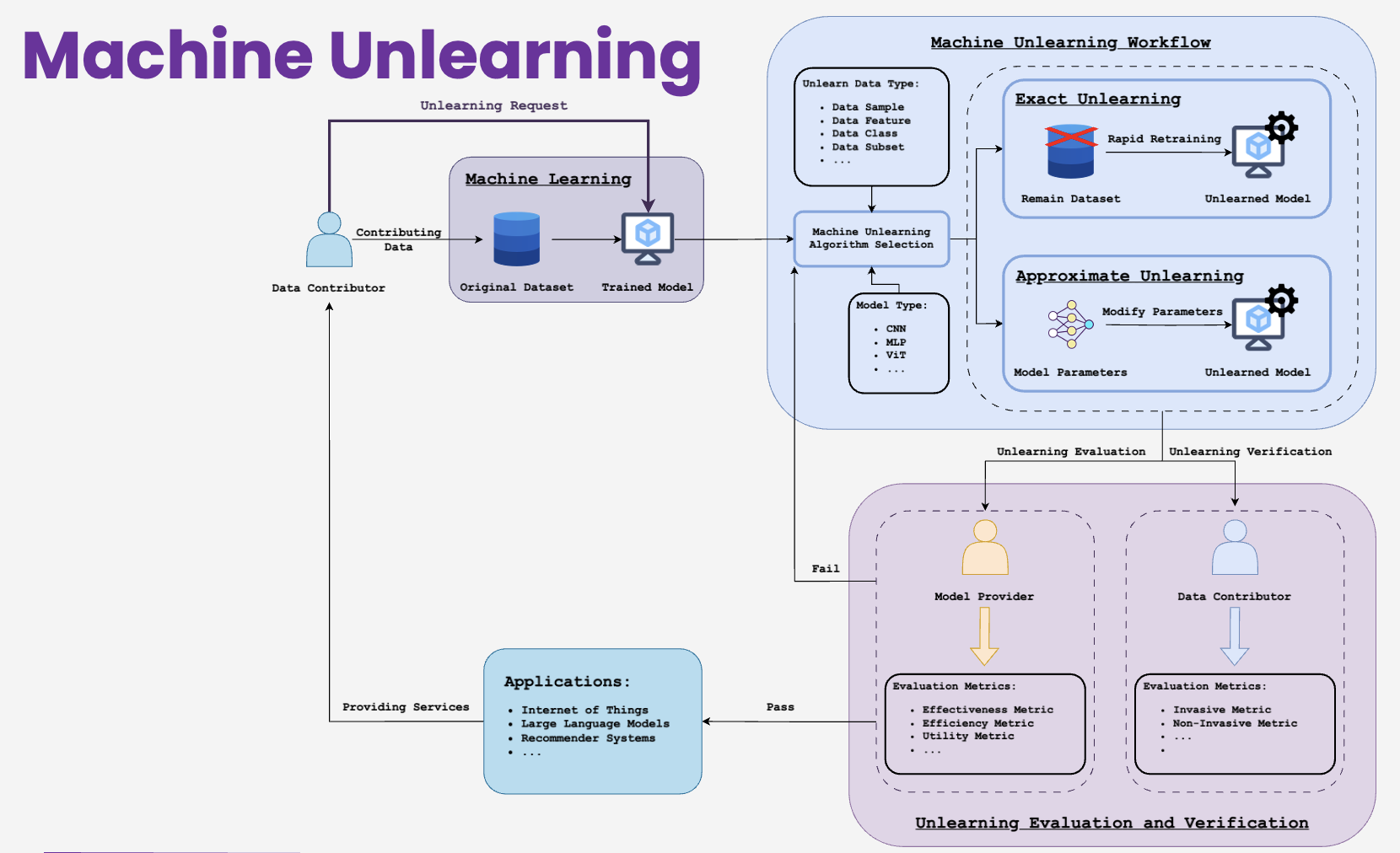
This observation emphasizes the need for robust and secure unlearning techniques in both image processing and robotics, especially methods that can effectively forget environment dynamics as well as data. Tackling these challenges is essential for building robotic systems that reliably adapt to new situations and comply with future regulatory requirements such as the AI Act [European AI Act]. An overview of a general machine unlearning framework is shown in Figure 1 .
Goal
My original goal was to explore recent advances and algorithms in the field of zero-shot machine unlearning, specifically, methods that do not require access to the original training data. Initially, I aimed to identify open questions or research directions worth pursuing. However, as I examined these algorithms more closely, I encountered several unexpected issues. What began as a brief investigation eventually evolved into a short report paper, which I presented at a local conference.
The goal of machine unlearning is to remove the influence of specific data from a model, such that the model behaves as if that data was never seen during training. While retraining from scratch is a theoretical gold standard, it is rarely practical in deployed systems.
Zero-shot unlearning approaches aim to bypass this retraining step entirely by using synthetic samples or targeted knowledge transfer [Chundawat et al. 2023]. These methods are being extended nowadays to RL and robotics, where real-world data is harder to reproduce and harder to delete.
In our paper, we analyze a state-of-the-art zero-shot unlearning pipeline and expose a critical limitation in its current formulation: even after successful forgetting, forgotten information can reappear with continued training.
Zero-Shot Unlearning
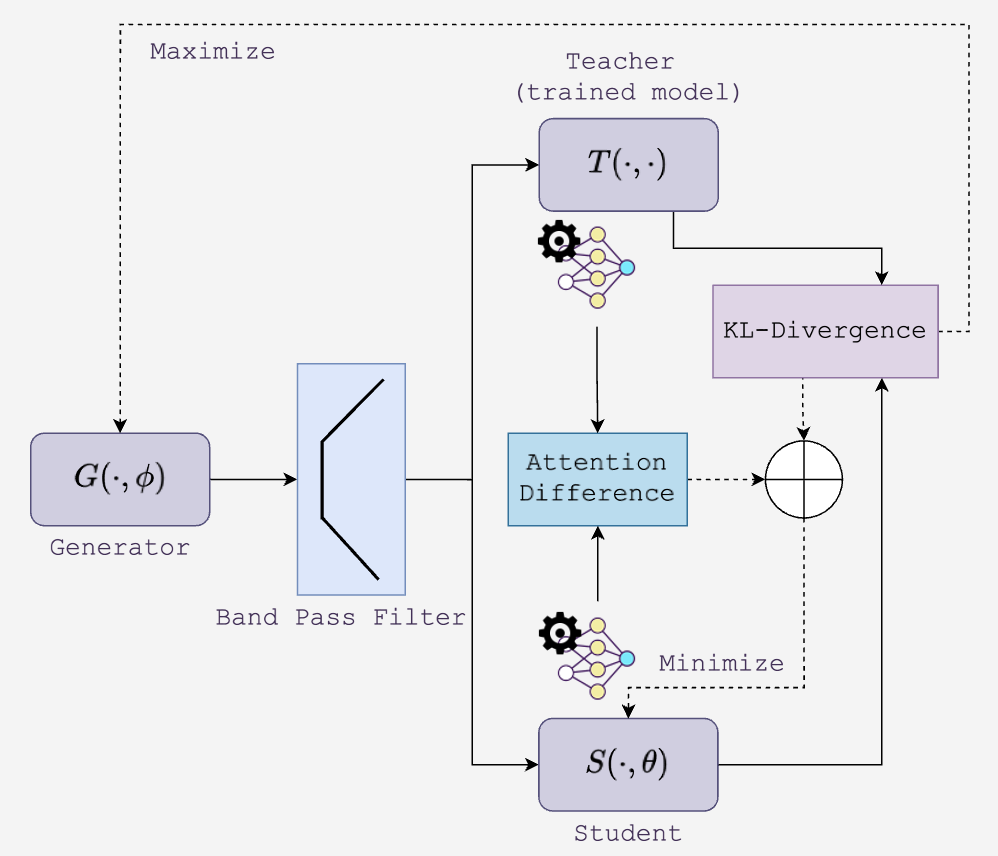
We implemented and extended the Gated Knowledge Transfer (GKT) pipeline proposed by [Chundawat et al. 2023], which enables forgetting without access to the original training data. The core components are:
- Teacher model: A pre-trained, frozen network trained on the complete dataset. It provides supervision in the form of class probability logits.
- Synthetic data generator: A generator network that produces candidate inputs from random noise. These inputs are passed through the teacher to produce synthetic predictions.
- Gating filter: A crucial filtering step that discards any samples predicted by the teacher to belong to the target forget class with high confidence. This ensures the student is never exposed to forget-class signals.
- Student model: A randomly initialized model that learns to mimic the teacher, but only on filtered samples associated with the retain set. Supervision is provided through KL-divergence between student and teacher logits.
Each pseudo-batch in training consists solely of synthetic, retain-class samples. The student is optimized to match the teacher on these safe samples, gradually forgetting the influence of the removed class. The complete GKT pipeline is illustrated in Figure 2 .
Related Methods
[Warnecke et al. 2023] proposed feature- and label-level unlearning, identifying and suppressing components most influenced by specific classes. [Singh et al. 2022] developed parameter attribution techniques to enable class-specific forgetting while preserving the rest of the network.
Other approaches aim to provide formal guarantees. [Ginart et al. 2019] introduced -approximate unlearning, inspired by differential privacy. [Guo et al. 2023] extended this with convex optimization and noise injection for certified data removal, but these often assume data access, which zero-shot unlearning avoids.
Black-box and prompt-based approaches, such as ALU (Agentic LLM Unlearning) [Sanyal et al. 2025], extend forgetting to models without internal access (a scenario increasingly common in deployed robotic systems with pre-trained perception modules).
In reinforcement learning, [Ye et al. 2024] introduced the term reinforcement unlearning, proposing:
- A decremental method that erases knowledge over time
- An environment poisoning method that misleads the agent
They also propose an environment inference metric to detect residual knowledge.
[Gong et al. 2024] introduced TrajDeleter, a two-phase offline RL method that first forgets trajectory influence, then stabilizes policy performance. It achieves high forgetting accuracy with minimal retraining.
Additional work by [Chen et al. 2023] addresses backdoor removal in RL via neuron reinitialization, which overlaps conceptually with targeted unlearning but serves robustness, not privacy.
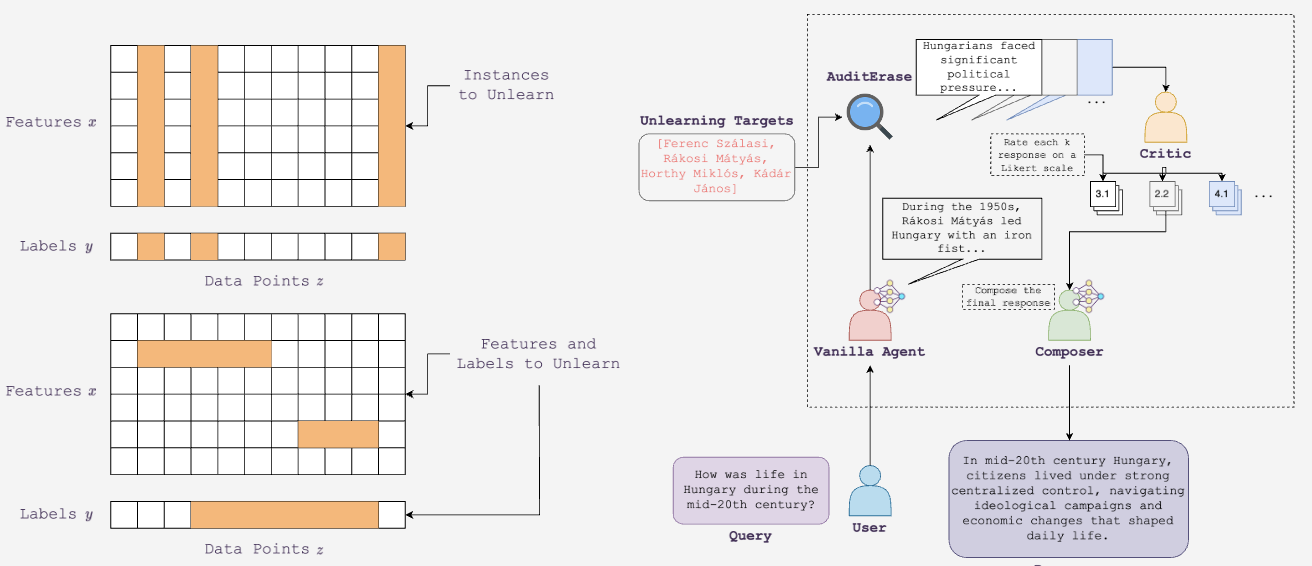
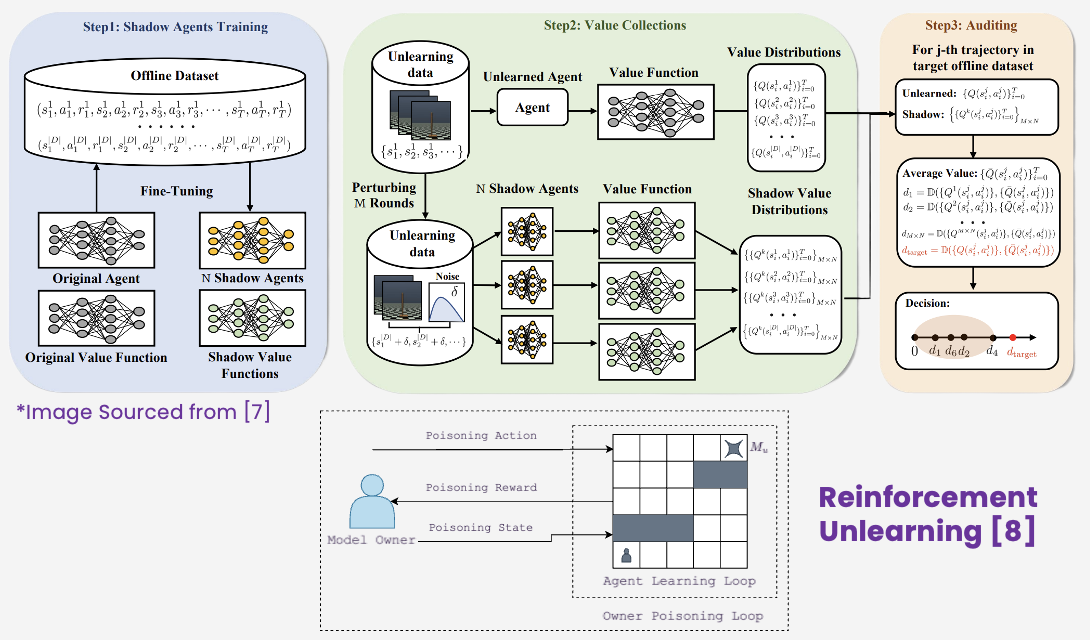
Finally, FRAMU by [Shaik et al. 2023] brings unlearning to federated RL, using attention to identify and remove private or outdated data without centralizing models. Figure 3 illustrates two perspectives on targeted unlearning, while Figure 4 compares reinforcement learning unlearning methods at trajectory and environment levels.
Our Method
We evaluated the stability and scalability of the Gated Knowledge Transfer (GKT) method [Chundawat et al. 2023] across multiple vision benchmarks. Our focus was on how long forgetting persists during continued pseudo-training, and how performance degrades as the number of classes to forget increases.
Following the zero-shot unlearning setup, a teacher model is first trained on the full dataset. A generator then produces synthetic samples, which are filtered to exclude those likely belonging to the forget class. The resulting samples are used to train a student model to mimic the teacher via KL-divergence. This pseudo-training is repeated for 2000 batches.
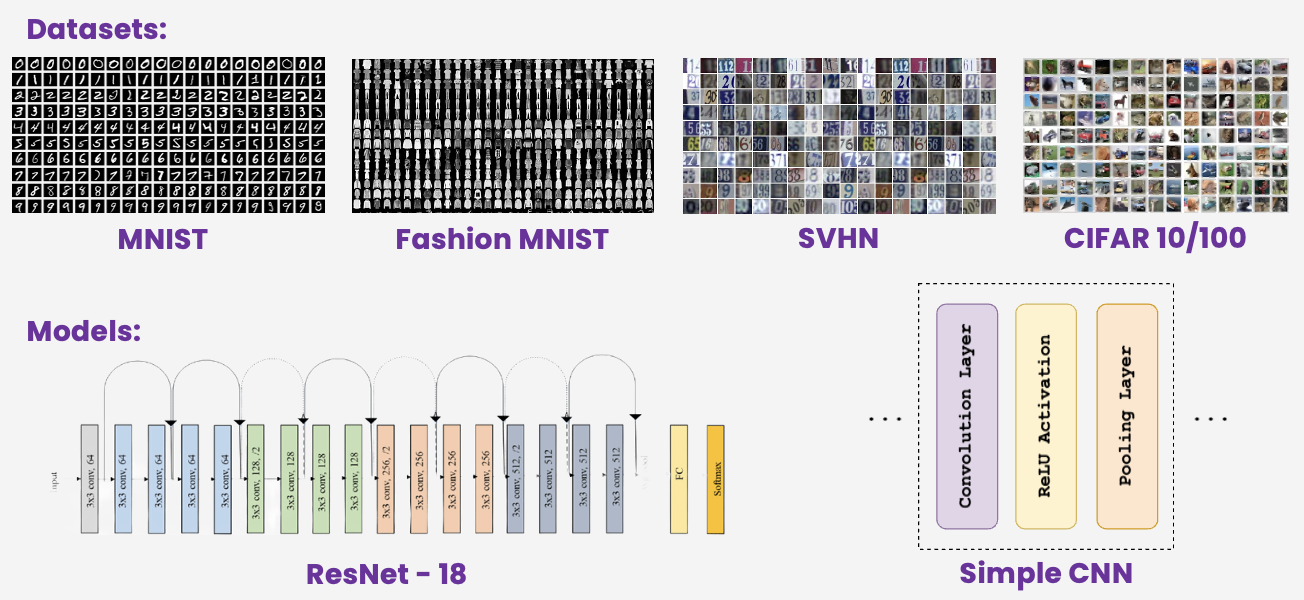
We test this pipeline on five datasets:
We compare two architectures:
- AllCNN: a lightweight network with 8 convolutional layers and no fully connected layers, relying on global average pooling.
- ResNet-18: a deeper architecture with residual skip connections.
Each model was evaluated over 10 independent random seeds to account for variance in initialization.
Two main metrics guide our analysis:
- Forget and retain accuracy after training
- The tipping point, when forget-set accuracy begins to rise again (indicating re-learning)
Finally, we scale the forget set size on CIFAR-10 (class 0 up to class 8) to understand how overlap and complexity influence unlearning. This setup helps reveal hidden failure modes in GKT, especially in settings where long-term deployment and compliance are critical. The datasets and architectures used in our experiments are summarized in Figure 5 .
Single-Class Forgetting: Stability Analysis
To evaluate the stability of GKT-based zero-shot unlearning, we measured its performance across five datasets and two architectures as mentioned before. The goal was to assess how well the method forgets a single class without damaging overall model performance. Table 1 summarizes our experimental results.
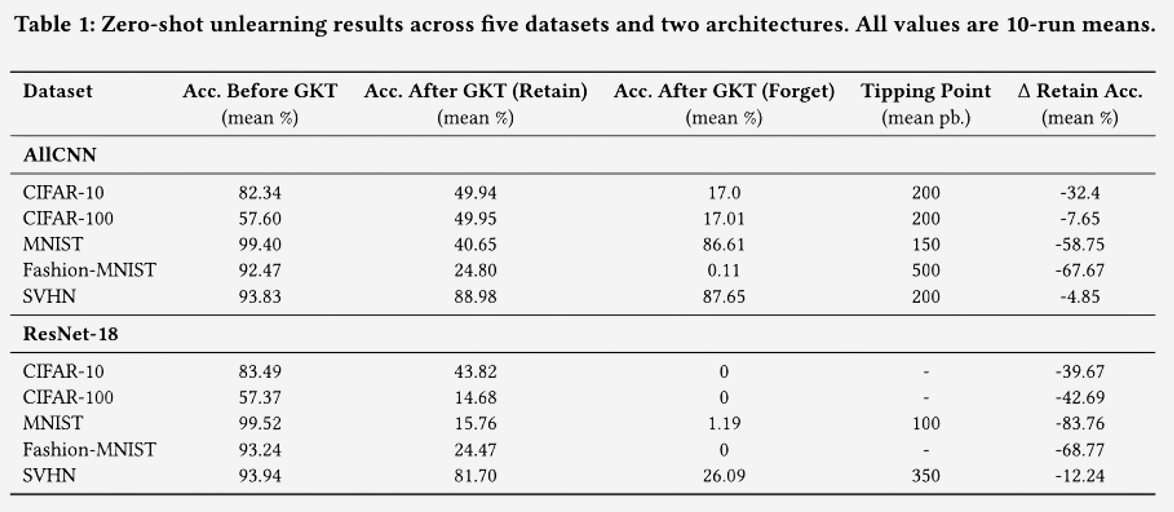
Our experiments reveal that forgetting is often unstable and not robust across datasets or architectures. In particular:
- On MNIST (AllCNN), the student model eventually re-learns the forget class, reaching 86.61% accuracy—almost identical to the teacher’s original performance. Meanwhile, retain accuracy collapses to 40.65%.
- SVHN shows delayed forgetting reversal, but still ends up with high forget-class accuracy, undermining the unlearning goal.
- Fashion-MNIST appears to succeed in forgetting (0.11%), but sacrifices nearly 68% of retain-set performance—a catastrophic tradeoff.
- CIFAR-10/100 degrade early, long before forget-class leakage appears.
Interestingly, switching to a deeper model (ResNet-18) improves suppression of the forget class in some cases (e.g., CIFAR-10: 0%), but this comes at the cost of heavy degradation on retained classes (e.g., MNIST: -83.76%).
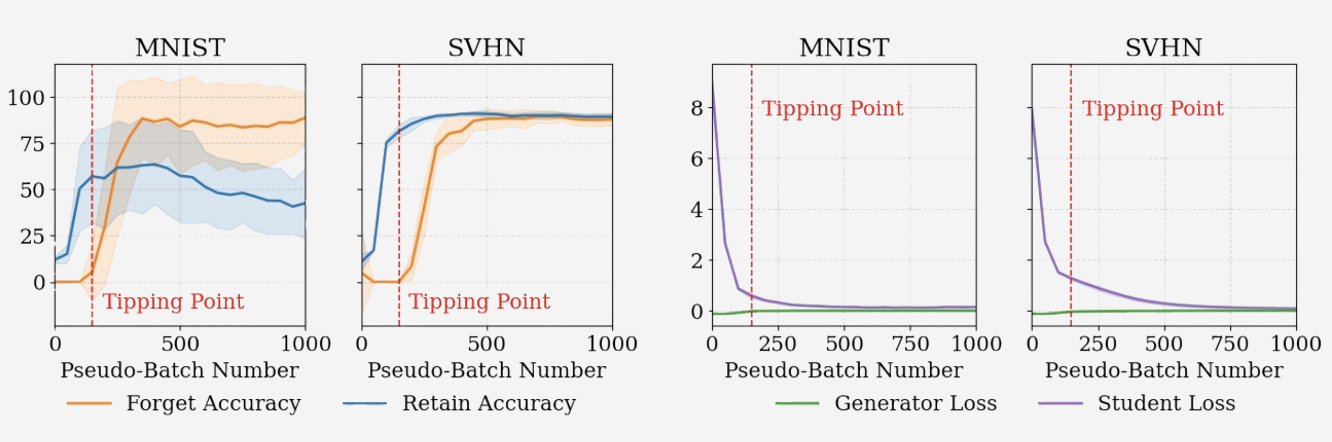
The graph above highlights a key failure mode: after a short stable interval, forget accuracy begins to rise, despite continued filtering. We call this the tipping point. This phenomenon suggests latent leakage from the generator or overfitting to shared features between retained and forgotten classes.
In short: zero-shot unlearning is highly brittle, with poor tradeoffs between forgetting effectiveness and knowledge retention. No configuration in our experiments produced stable long-term forgetting without harming overall utility. The retain and forget accuracy curves for MNIST and SVHN are shown in Figure 6 , highlighting the tipping point phenomenon.
Multi-Class Forgetting: Scaling Issues
To test scalability, we incrementally increased the forget set on MNIST from 1 to 3 to 5 classes. We tracked how both retain and forget accuracies evolved during pseudo-training. Surprisingly, adding more forget classes caused the tipping point to occur earlier, narrowing the safe unlearning interval, as shown in Figure 7 .
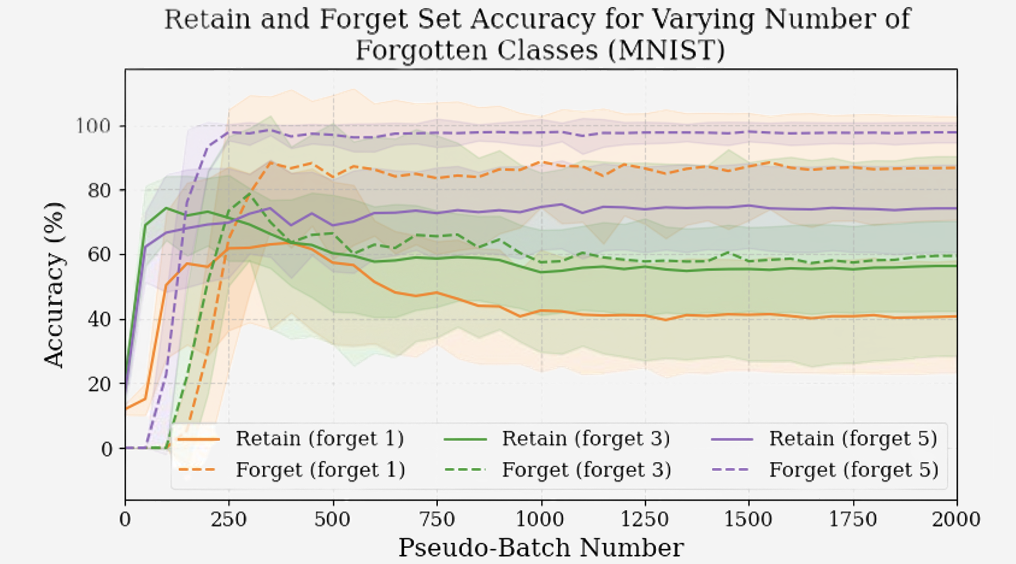
These findings confirm that GKT fails to scale to real-world scenarios where more than one class must be forgotten securely.
Conference Presentation
I had the opportunity to present my preliminary findings at the first Intelligent Robotics Fair, held in Hungary in 2025. The goal was to introduce the research community to the emerging field of machine unlearning, and to highlight the current limitations of approximate, data-free unlearning methods.
In particular, I emphasized the significant headroom for progress in scenarios where training data is inaccessible due to privacy regulations or legal constraints.
The full version of this work will be published in the ACM Conference Proceedings as part of the event’s official publication.

@inproceedings{10.1145/3759355.3759625,
author = {Takács, Tamás and Gulyás, László},
title = {Failure Modes of Zero-Shot Machine Unlearning in Reinforcement Learning and Robotics},
year = {2025},
isbn = {9798400715891},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3759355.3759625},
doi = {10.1145/3759355.3759625},
pages = {76–81},
numpages = {6},
keywords = {Machine Unlearning, Zero-Shot Unlearning, Reinforcement Learning, Robotics, Machine Learning Security, Data Privacy},
location = {Budapest, Hungary},
series = {IntRob '25}
}