Targeted Behavioral Unlearning for Discrete On-Policy Reinforcement Learning
Tamás Takács1 & László Gulyás1
1ELTE Eötvös Loránd University, Department of Artificial Intelligence, Budapest, Hungary
Both authors contributed equally to this research.
[Paper][Code][Poster][Presentation]
Accepted at the Intelligent Robotics Fair (IntRob 2026), Budapest, Hungary. Also presented as a poster at the AI Symposium 2026.
Abstract
Machine unlearning in reinforcement learning (RL) has focused on forgetting entire environments or trajectory classes. However, practical safety and compliance requirements often demand finer control: selectively removing specific behaviors tied to regions of the state space, while preserving the agent’s overall competence.
We introduce targeted behavioral unlearning, a method for on-policy RL agents that identifies and unlearns transitions occurring within a designated forget region of the state space. Our approach uses trajectory-selective gradient adjustment on a pre-trained PPO agent, filtering unlearning updates to only those time steps where the agent exhibits the unwanted behavior.
We evaluate on two environments:
- CartPole (forget right-side balancing): from 36.5% to 3.8% forget-region occupancy in 500 gradient steps, with perfect returns (500 / 500) maintained.
- LunarLander (forget tilted flight): the only approach that preserves returns while reducing tilted flight, where random forgetting collapses performance in some seeds.
Compared to full retraining, which requires three orders of magnitude more steps and degrades returns from 500 to 79, and fine-tuning, which requires 100× more steps and exhibits unstable convergence, our method achieves comparable forget effectiveness in two to three orders of magnitude fewer gradient updates, while maintaining task performance and demonstrating consistent behavior modification where random forgetting fails.
Introduction
As reinforcement learning agents are deployed in safety-critical and regulated domains, robotics, autonomous control, decision-support systems, the ability to correct learned behavior after training becomes essential. Existing approaches face a difficult trade-off: full retraining is expensive and may degrade competence, while fine-tuning requires environment access and often exhibits unstable convergence.
Prior work on reinforcement unlearning (Ye et al. 2024, Gong et al. 2024) targets either entire environments or pre-collected trajectory batches as atomic forget units. But many real-world scenarios are finer-grained. The unwanted behavior is not “everything the agent learned in environment X”, it is “the way the agent behaves in this specific region of the state space”. A single trajectory may contain both safe and unsafe transitions, and we need to remove only the latter.
This paper introduces targeted behavioral unlearning: a method for on-policy RL agents that:
- identifies trajectories visiting a designated forget region,
- filters them to the specific time steps where the behavior occurs,
- applies a gradient-adjustment loss combining gradient ascent on forget steps, gradient descent on retain steps, and a parameter-anchor penalty.
The result is rapid, monotonic convergence with no environment access required.
Related Work
Machine Unlearning in Supervised Learning
Machine unlearning aims to remove the influence of specific data from trained models. [Ginart et al. 2019] introduced exact unlearning via model reconstruction, while [Guo et al. 2020] proposed approximate methods that modify the existing model to emulate that effect. Zero-shot approaches such as the Gated Knowledge Transfer (GKT) method by [Chundawat et al. 2023] operate without access to original training data. These methods are designed for classification and do not account for the sequential, interactive nature of RL, as we analyzed in our [previous work on zero-shot unlearning failure modes].
Unlearning in Reinforcement Learning
[Ye et al. 2024] introduced reinforcement unlearning for multi-environment settings. They propose decremental RL (minimizing Q-values in the target environment) and environment poisoning (corrupting transitions to overwrite learned behavior). A key finding is that learning from scratch (LFS), retraining on only the retain environments, fails as a baseline because the agent’s representations generalize across environments, making it difficult to isolate and remove specific knowledge. They also observe over-unlearning: aggressive forgetting can degrade retain-environment performance.
[Gong et al. 2024] propose TrajDeleter for offline RL, applying a two-phase strategy: minimizing the value of forgotten trajectories, then stabilizing retained performance. TrajDeleter operates on Q-learning agents and pre-collected trajectory datasets.
Our work differs from both in three respects:
- We target behavioral / spatial unlearning within a single environment, not environment-level or trajectory-batch forgetting.
- We operate on on-policy policy-gradient methods (PPO), not Q-learning.
- We introduce step-level filtering: unlearning only the specific time steps where the unwanted behavior occurs, rather than treating entire trajectories as atomic forget units.
Continual and Curriculum Learning
Continual learning addresses accidental forgetting: how to accumulate new skills without losing old ones (catastrophic forgetting). Techniques such as EWC, PackNet, and experience replay protect important parameters or replay stored transitions.
Our work is the deliberate inverse: we intentionally induce selective forgetting of targeted behaviors. The mechanisms share a common foundation, both manipulate gradient updates over subsets of experience and both balance competing objectives, but the optimization objective is reversed. Where EWC constrains parameter updates to protect prior task performance, our method constrains updates to destabilize specific behavioral regions while protecting others.
Problem Formulation
Consider an RL agent with policy trained in an environment with state space and action space . We define a forget region as a subset of the state space where the agent exhibits behavior that should be removed. The complementary retain region is .
Given a set of stored trajectories collected by the trained agent, we partition each trajectory’s time steps into forget steps and retain steps .
The behavioral unlearning objective is to find parameters such that:
- Forget effectiveness: the agent under rarely visits during evaluation (forget-region fraction is low).
- Retain stability: the ratio of post-unlearning to pre-unlearning mean episode return is close to 1.
- Selectivity: forgetting is spatially targeted, the agent avoids without unnecessarily degrading behavior in .
This formulation differs from prior work in a key way: the forget target is a region of the state space, not a discrete environment or trajectory set. A trajectory may pass through both and , and we must unlearn only the former.
Method
Our method, trajectory-selective behavioral unlearning, operates on a trained PPO agent and its stored rollout trajectories. The procedure has three phases.
Step 1: Identify Forget Trajectories
Given the forget-region specification and stored trajectories , we identify forget trajectories: those containing at least one time step where . Formally:
Step 2: Step-Level Filtering
Rather than treating forget trajectories as atomic units, we filter to individual time steps. When sampling a mini-batch from for the unlearning gradient, we include only those transitions where . This prevents dilution: without filtering, a trajectory with 30% of steps in would contribute 70% retain-region transitions to the forget gradient, weakening the unlearning signal.
Step 3: Gradient Adjustment
At each unlearning step, we sample a forget batch (filtered to steps) and a retain batch (from , unfiltered). The loss combines three terms:
- The first term performs gradient ascent on the policy loss for forget-region transitions, pushing the agent away from actions it would take in .
- The second term performs standard gradient descent on retain transitions, preserving competence.
- The anchor term penalizes large parameter deviations from the original , preventing catastrophic drift. Without it, gradient ascent on the forget batch can destabilize the entire policy within a few steps.
We set and find results stable across . Combined with a small learning rate (, 30× lower than training), these safeguards ensure gradual, controlled modification.
Experimental Setup
We evaluate on two Gymnasium environments with distinct forget scenarios:
-
CartPole-v1 (left-only). The agent balances a pole on a cart (4D state, 2 discrete actions). The forget region is , the right half of the track. A trained agent spends 36.5% of time there, the goal is left-only balancing.
-
LunarLander-v3 (no-tilt). The agent lands a spacecraft (8D state, 4 discrete actions). The forget region is , tilted flight beyond 0.2 radians. A trained agent spends 18.9% of time tilted.
Both baseline agents use PPO with shared two-layer MLPs (64 units, tanh), separate policy / value heads, Adam (), GAE (, ), clip , entropy coefficient 0.01, and 2,048-step rollouts. CartPole trains for 500K steps (perfect returns), LunarLander for 2M steps (mean return ≈ 230). Trajectories (1,000 per environment) are stored during evaluation for use in unlearning.
We compare against four baselines:
- Full retraining (CartPole only). Fresh agent from scratch, reward function with −1 penalty in , 500K steps.
- Fine-tuning with reward shaping. Same warm-start checkpoint, reward shaping (−1 in ), 50K steps.
- Random trajectory forgetting. Same algorithm but with randomly selected forget trajectories.
- No step filtering (ablation). Correct trajectory selection but without step-level filtering.
All methods run with seeds 42, 43, 44.
Results
CartPole: Two to Three Orders of Magnitude Fewer Updates
| Method | Steps | Return | FRF ↓ | Retain Stab. ↑ | Cart Pos. |
|---|---|---|---|---|---|
| Original agent | n/a | 500.0 ± 0.0 | 0.365 ± 0.175 | n/a | −0.046 |
| Ours (traj. selective + filter) | 500 | 500.0 ± 0.0 | 0.038 ± 0.005 | 1.00 | −0.655 |
| No step filtering (ablation) | 500 | 500.0 ± 0.0 | 0.043 ± 0.008 | 1.00 | −0.407 |
| Random trajectory forget | 500 | 500.0 ± 0.0 | 0.427 ± 0.291 | 1.00 | −0.023 |
| Fine-tuning (warm start) | 50,000 | 500.0 ± 0.0 | 0.043 ± 0.009 | 1.00 | n/a |
| Full retraining (from scratch) | 500,000 | 79.1 ± 22.3 | 0.057 ± 0.022 | 0.16 | n/a |
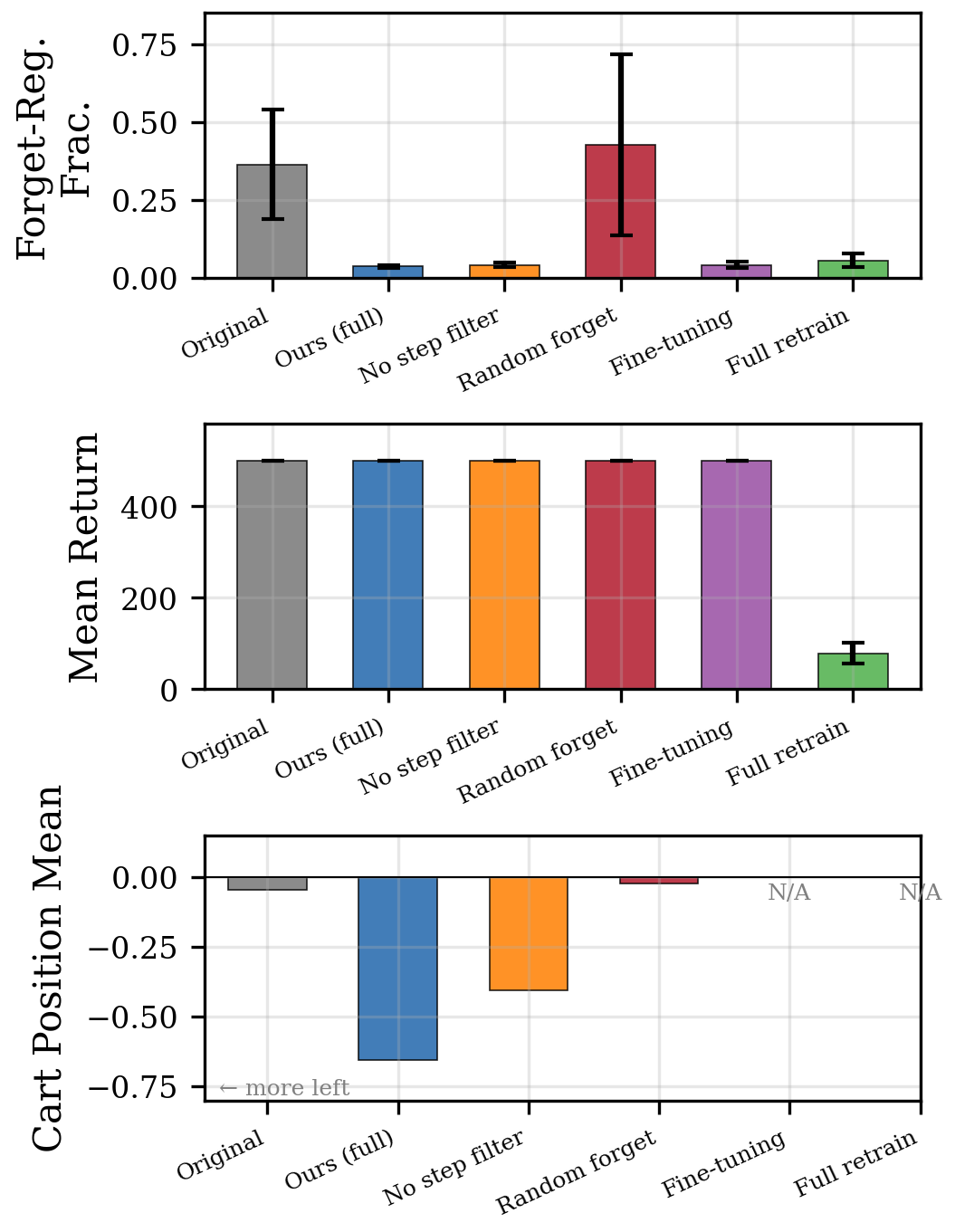
Our method reduces forget-region occupancy from 36.5% to 3.8% in 500 gradient steps, while maintaining perfect returns. Full retraining achieves comparable forget-region reduction (5.7%) but requires 500,000 steps and suffers severe performance degradation (returns drop to 79.1, retain stability of 0.16).
Targeted Selection is Essential
Random trajectory forgetting produces highly inconsistent results (FRF ). In one seed, random forgetting increased the forget-region fraction from 0.51 to 0.76, the agent spent more time on the right side after “unlearning.” This validates that scenario-aware trajectory selection is not merely an optimization but a correctness requirement: unlearning the wrong transitions can push the policy in arbitrary directions.
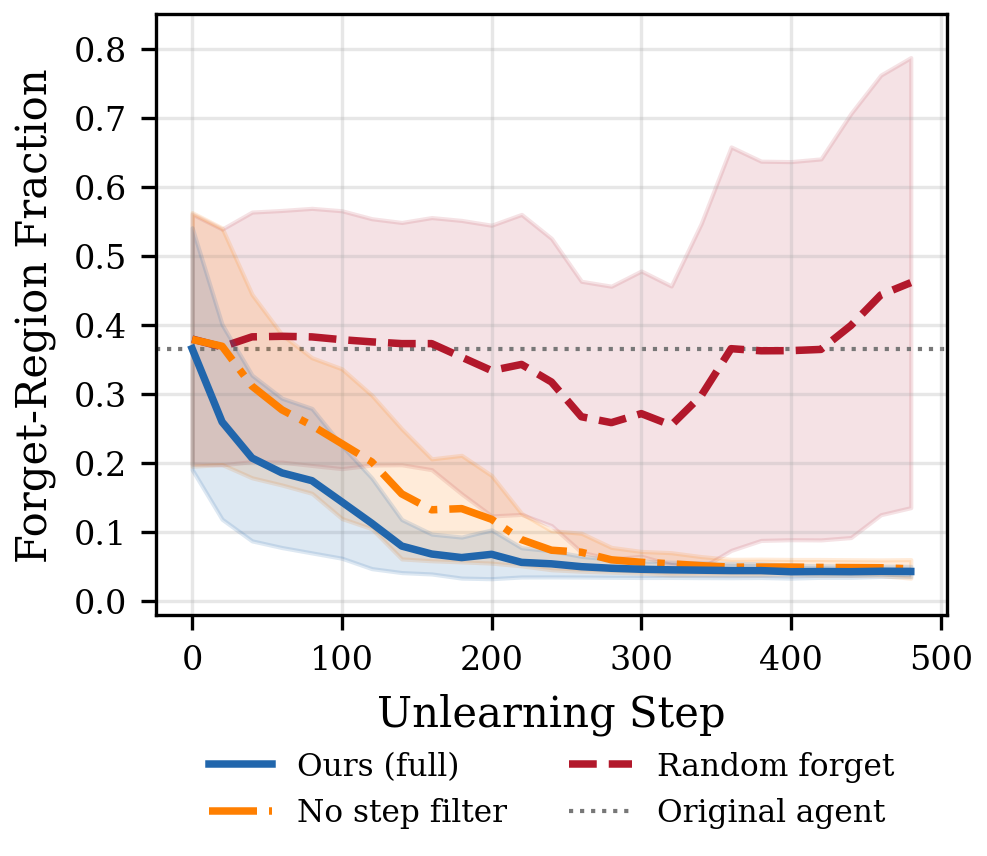
Step-Level Filtering Improves Behavioral Precision
The no-step-filtering ablation achieves comparable forget-region fraction (0.043 vs. 0.038) but a notably weaker behavioral shift: the mean cart position is −0.407 compared to −0.655 for our full method. This 38% reduction in leftward displacement shows that without filtering, the retain-region steps in forget trajectories dilute the gradient.
Fine-Tuning is Unstable
Fine-tuning from the same warm-start checkpoint with reward shaping achieves comparable final FRFs while preserving returns. However, the training trajectory is highly unstable: FRF oscillates between 0.03 and 0.95 (mean across checkpoints), and intermediate checkpoints frequently exhibit near-total forget-region occupancy. Fine-tuning also requires environment interaction, which may not be available post-deployment. Our method converges monotonically using only stored trajectories, in 100× fewer steps.
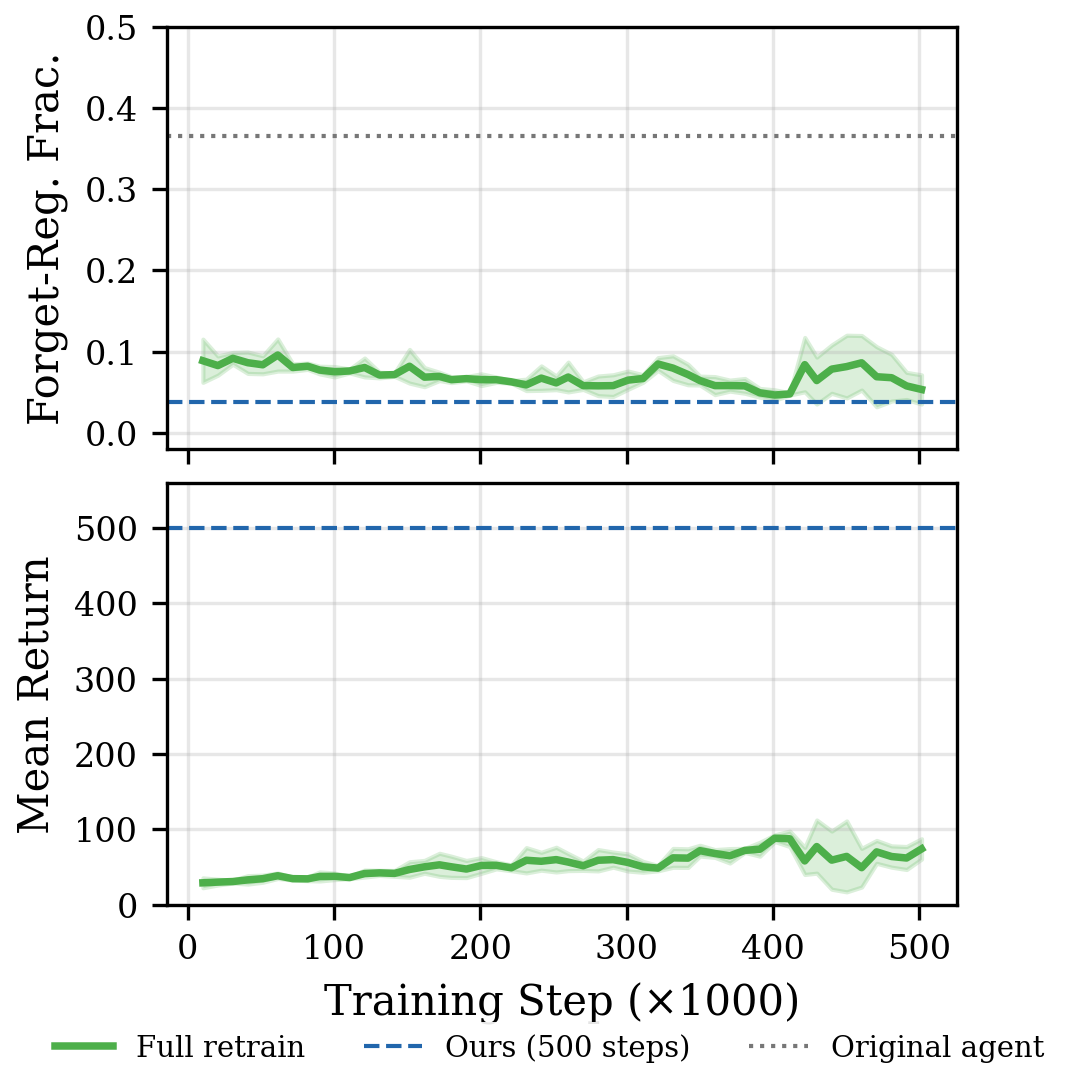
LunarLander: Generalization
| Method | Steps | Return | FRF ↓ | Retain Stab. ↑ |
|---|---|---|---|---|
| Original agent | n/a | 230.5 ± 95.8 | 0.189 | n/a |
| Ours | 500 | 231.4 ± 11.5 | 0.154 ± 0.030 | 1.00 |
| Random forget | 500 | 192.8 ± 52.3 | 0.177 ± 0.063 | 0.84 |
| Fine-tuning | 50,000 | 269.9 ± 1.7 | 0.103 ± 0.038 | 1.17 |
Fine-tuning achieves stronger forgetting (0.103 vs. our 0.154) but requires 100× more steps and environment access. Crucially, our method is the only unlearning approach that fully preserves returns (231.4 vs. 230.5 baseline, retain stability 1.00). Random forgetting drops returns by 16% to 192.8, with one seed collapsing to 132.2.
Per-Seed Reliability
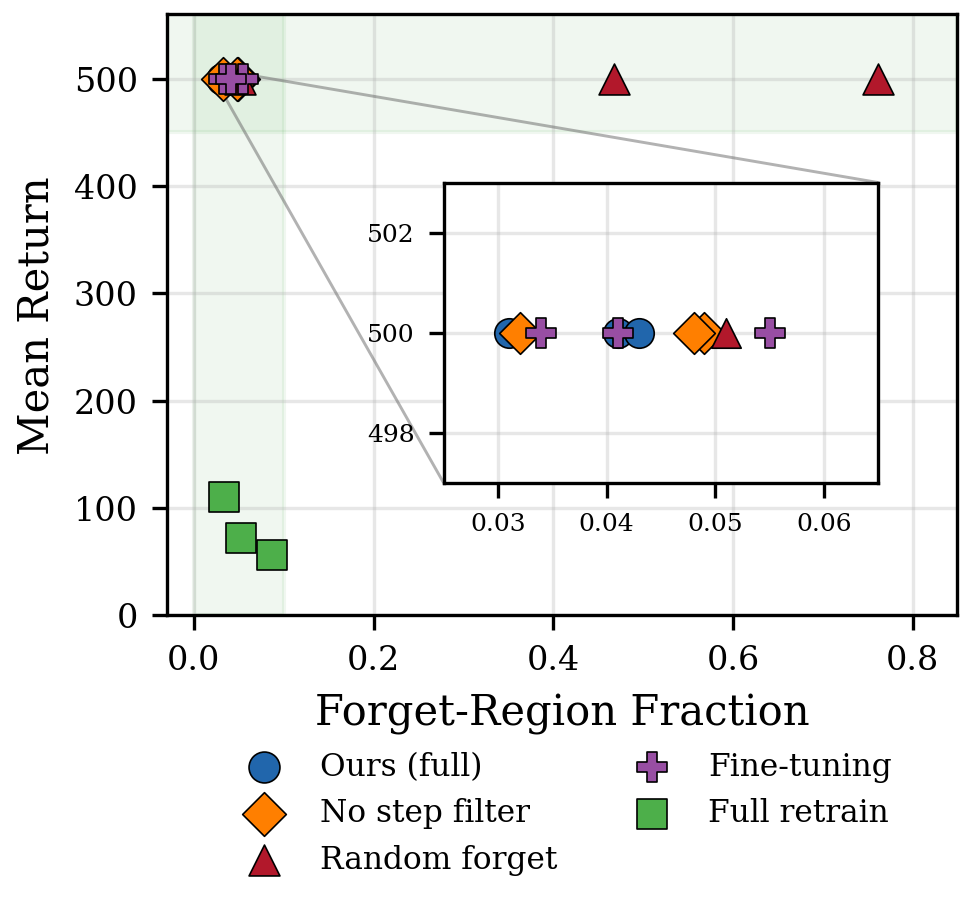
Each baseline has a distinct failure mode:
- Full retraining fails on retain stability,
- Random forgetting fails on forget effectiveness,
- Fine-tuning clusters with our method but requires 100× more steps.
Only targeted behavioral unlearning succeeds on both dimensions efficiently.
Discussion
Positioning within RL unlearning. Our baselines exhibit different failure modes than those in prior work. Ye et al. (2024) find that retraining fails because representations generalize across environments. In our single-environment setting, retraining succeeds at forgetting but at enormous cost and with severe performance degradation. Both works observe over-unlearning, our anchor term and low learning rate prevent policy collapse, analogous to their finding. Existing methods span a granularity spectrum: environment-level, trajectory-level, and our step-level approach. Finer granularity is essential when the forget target is a continuous state-space property.
Behavioral vs. data-level unlearning. Traditional unlearning removes specific data points. Behavioral unlearning removes behaviors, state-action associations in a policy. The same trajectory may contain both desirable and undesirable behaviors, requiring step-level treatment. Our ablation quantifies this: omitting step-level filtering reduces the behavioral shift by 38%.
Limitations. Both environments use discrete action spaces and relatively low-dimensional states. Real-world applications may involve continuous actions, high-dimensional observations, and more complex forget-region geometries. The method requires stored trajectories, agents deployed without trajectory logging would need alternative approaches. Our evaluation is limited to PPO. Finally, we do not yet provide formal guarantees that forgotten behavior cannot be recovered through fine-tuning or adversarial probing.
Future Work
Several directions remain open:
- Continuous-control tasks (e.g. MuJoCo) and high-dimensional observation spaces, to test whether step-level filtering generalizes to richer domains.
- Formal unlearning guarantees analogous to -approximate unlearning in supervised learning, to strengthen applicability in regulated domains.
- Robustness to recovery attacks: can an adversary recover the forgotten behavior through fine-tuning?
- Combining behavioral unlearning with continual learning safeguards to enable agents that both acquire and selectively forget skills in a unified framework.
Conclusion
We introduced targeted behavioral unlearning for on-policy RL agents, a method that selectively removes behaviors associated with specific regions of the state space. Our trajectory-selective approach with step-level filtering achieves comparable forget effectiveness in two to three orders of magnitude fewer gradient updates than fine-tuning or retraining baselines, while maintaining task performance, and demonstrates consistent, reliable forgetting where random trajectory selection fails.
Our ablation study reveals a two-level hierarchy of importance:
- Which trajectories to unlearn matters most, random selection produces unreliable and sometimes counterproductive results.
- Which steps within those trajectories to target provides further precision, improving the strength of the behavioral shift by 38%.
Together, these findings establish that behavioral unlearning in RL requires careful, granular targeting at both the trajectory and transition level. These results, validated across two environments with different forget criteria (position-based and orientation-based), position behavioral unlearning as a distinct and practically important problem in RL, complementary to existing environment-level and trajectory-level approaches, and orthogonal to continual learning methods.
Acknowledgements
Supported by the EKÖP-25 University Research Scholarship Program of the Ministry for Culture and Innovation from the source of the National Research, Development and Innovation Fund.

@inproceedings{takacs2026behavioral,
author = {Tak\'acs, Tam\'as and Guly\'as, L\'aszl\'o},
title = {Targeted Behavioral Unlearning for Discrete On-Policy Reinforcement Learning},
booktitle = {Proceedings of the Intelligent Robotics Fair (IntRob)},
year = {2026},
publisher = {Association for Computing Machinery},
address = {Budapest, Hungary},
series = {IntRob '26}
}back to papers