Trajectory Separation for Scalable Credit Assignment in Cooperative Multi-Agent Reinforcement Learning
Tamás Takács1,László Gulyás1,&Gergely Magyar1
1ELTE Eötvös Loránd University, Department of Artificial Intelligence, Budapest, Hungary
[Paper][Code][Poster][Presentation]
Accepted at the International Conference on Computational Collective Intelligence (ICCCI 2026). An early version was presented as a poster at the Magyar Machine Learning Találkozó (Hungarian ML Conference) in Budapest.
Abstract
Credit assignment in multi-agent reinforcement learning (MARL) is especially challenging with shared global rewards where individual contributions are difficult to disentangle, often causing the “lazy agent” phenomenon. We propose trajectory separation within the Proximal Policy Optimization (PPO) framework: a shared encoder processes all observations in a single forward pass, while per-entity trajectories isolate individual contributions to learning signals. This reduces inter-agent interference and enables fine-grained credit assignment without specialized architectures.
Evaluated in the Lux AI environment, a large-scale, competitive multi-agent benchmark from the NeurIPS 2023 competition, our method achieves:
- 14× the resource throughput of global-trajectory variants
- +240% returns over IPPO and +1,282% over MAPPO
- 200K parameters and two hours of training, compared to 6.08M parameters and two days for the best competition RL entry
Ablation analysis confirms that each component of trajectory separation, per-entity rewards, critics, and advantages, is individually necessary, with per-entity rewards being the most critical (−78% throughput when removed). We further demonstrate that prioritizing data quality via trajectory separation outperforms increasing data quantity: a single highest-advantage training sample recovers 86% of full separation performance.
Introduction
Multi-agent reinforcement learning has produced striking emergent behaviors at scale, from large competitive benchmarks like Dota 2 and StarCraft II to research-grade environments such as Melting Pot and Lux AI. Centralized Training with Decentralized Execution (CTDE) became the workhorse paradigm, combining local observations with a shared global reward, but relying solely on a global reward obscures individual contributions and slows convergence.
We address this with a hybrid MARL framework that decomposes the global reward per entity and structures training into distinct trajectories for each agent group, providing clearer learning signals while still maintaining shared representations.
Motivating Paradoxes
When a MARL system trains with a single shared trajectory, poor credit assignment produces three concrete pathologies:
- Posthumous reinforcement. Actions by surviving agents retroactively reinforce a deceased agent’s past behaviors, because the destroyed agent’s transitions remain in the shared rollout.
- Inherited credit. Newly spawned entities inherit reinforcement from prior entities despite no causal involvement in the rewarded outcomes.
- Diluted signals. Shared rewards reinforce all agents equally, diluting the per-agent gradient as team size grows.
Our trajectory separation mechanism is designed to eliminate all three at the source, before the PPO update sees them.
Related Work
A central challenge in cooperative MARL is the credit assignment problem: determining each agent’s contribution to the team’s global reward.
Value factorization methods such as [VDN], [QMIX], Weighted QMIX, and QPLEX decompose the joint action-value into per-agent terms, but impose structural constraints (additive, monotonic, or mixing-network-based) and remain value-based, limiting scalability.
Policy-gradient approaches include [COMA] (counterfactual baselines), HAPPO (sequential trust-region updates), FACMAC (factored continuous critics), and MAT (attention-based sequence modeling). Newer work like ACAF and PRD targets asynchronous coordination and partial reward decoupling, respectively. All of these methods introduce specialized architectures or update schemes that add complexity and may not scale gracefully.
In contrast, our trajectory separation method operates directly at the trajectory level within standard PPO, requiring no mixing networks, sequential updates, or attention mechanisms. While the individual ingredients exist in isolation, prior work has not combined them at the trajectory level: value factorization decomposes the value function but maintains a single joint trajectory, IPPO decomposes networks but shares the global reward. Trajectory separation decomposes the training signal itself: each entity maintains its own reward stream, value baseline, and advantage estimate while sharing a single encoder.
Background
We model the multi-agent setting as a Markov Decision Process , where agents maximize expected discounted return . Proximal Policy Optimization (PPO) stabilizes updates via a clipped surrogate objective:
where is the importance sampling ratio and is the GAE-estimated advantage.
In the CTDE paradigm, MAPPO applies PPO with a centralized critic conditioning on the global state, and IPPO trains each agent independently with only local observations. Both serve as strong baselines but neither decomposes rewards or trajectories at the individual agent level.
Trajectory Separation
We combine trajectory separation with shared feature extractors, allowing individual agent contributions to be evaluated independently while utilizing common perceptual representations.
Let denote a set of agent groups. Each group generates its own trajectory , and the entity-specific reward is derived from environment interactions as:
The trajectory separation mechanism decouples these trajectories. A single environment step yields parallel training samples, improving the resolution of credit assignment without altering the PPO loss formulation. The total policy loss aggregates over all groups:
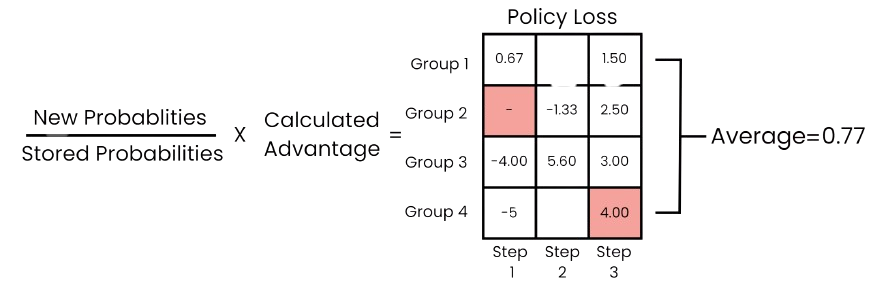
To correctly terminate trajectories, each of the groups maintains its own done flag: a group is marked done when all its constituent agents become inactive (e.g. destroyed or out of power), computed as the logical conjunction over member agents’ termination states. Crucially, groups can terminate at different timesteps within the same episode.
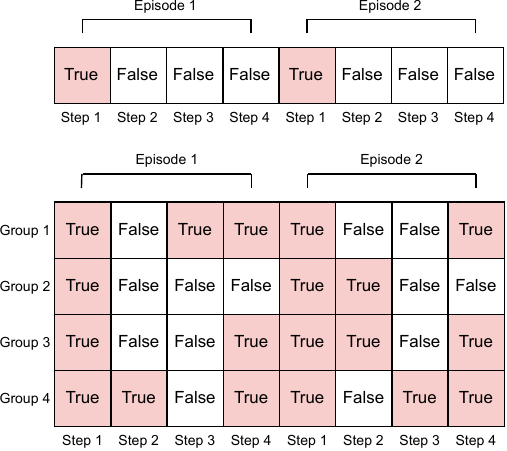
Distinction from Independent Learning (IPPO)
While trajectory separation shares the per-entity focus of independent learning, three key differences explain its superior performance:
- Shared encoder. TS uses a single forward pass with shared features, enabling implicit coordination, whereas standard IPPO uses fully independent networks. In our experiments, all methods share the same architecture for a fair comparison.
- Per-entity value estimation. TS computes separate value estimates capturing both local and team-level information, IPPO uses only local estimates.
- Localized rewards. TS assigns entity-specific rewards proportional to individual contributions, IPPO broadcasts team reward equally, diluting credit.
Architecture and Environment
We adopt a pixel-to-pixel architecture: a convolutional encoder processes the global spatial observation, producing per-pixel outputs from which agent actions are derived at their respective positions. The shared backbone uses residual blocks with batch normalization, Leaky ReLU activations, and Squeeze-and-Excitation modules, with spectral normalization to stabilize training. Actor and critic networks share this backbone but use separate weights to avoid conflict between policy optimization and value estimation objectives.
Lux AI is a fully observable, turn-based 2D grid game where teams manage factories and mobile units to collect Ice and Ore under power and terrain constraints. We selected it because it provides large-scale, dynamic multi-agent coordination with long time horizons and spatial reasoning, with a NeurIPS-sponsored competition baseline to compare against.
Results
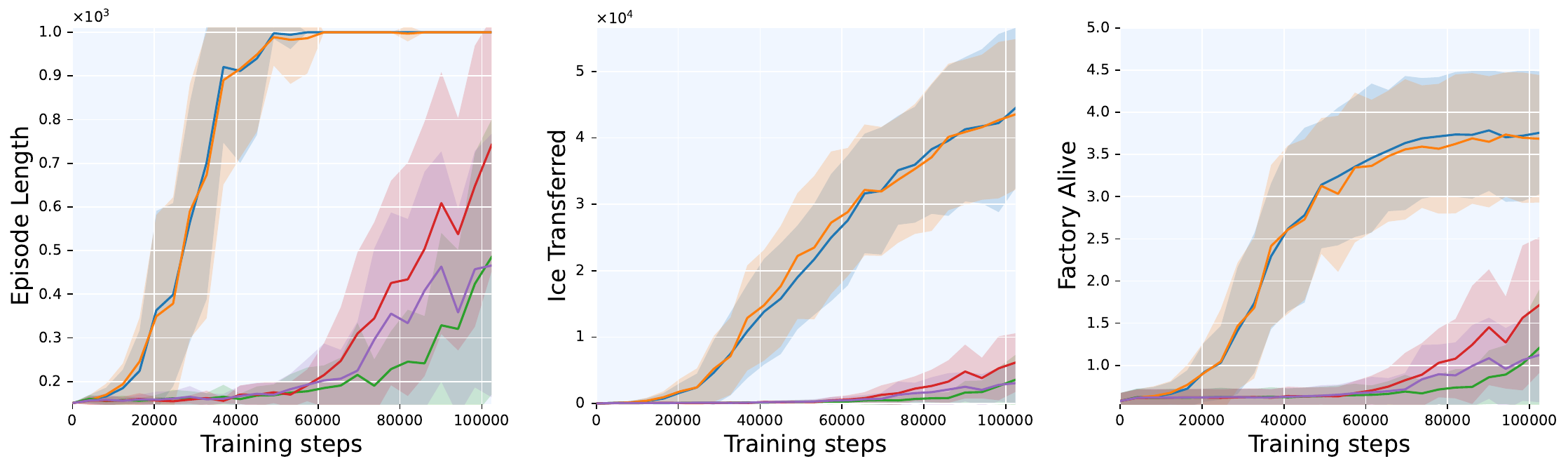
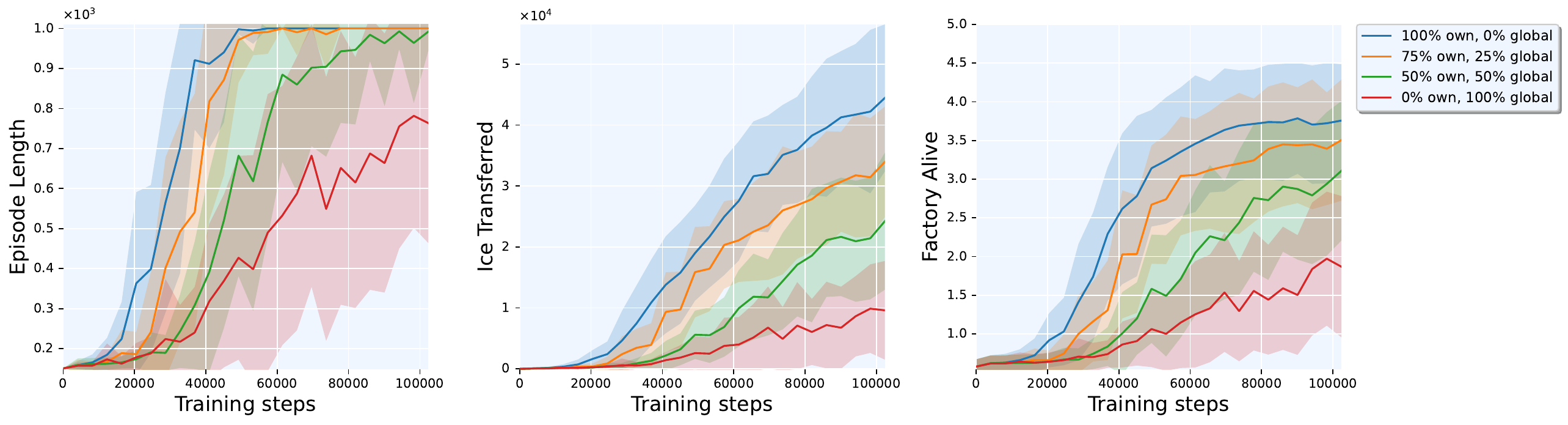
Global Trajectory vs. Separated Trajectories
Separated trajectory variants significantly outperform global trajectory variants. The separated approach enables agents to transfer over 40,000 ice to factories per episode, higher than the global variant, while keeping factories alive for the full 1,000-step episode.
| Variant | Ice Transferred | Episode Length |
|---|---|---|
| Sep. all (ours) | 44,472 ± 12,065 | 1,000 ± 0 |
| Global fact., sep. units | 43,528 ± 11,327 | 1,000 ± 0 |
| Sep. fact., global units | 3,573 ± 3,753 | 485 ± 315 |
| Global fact., global units | 6,162 ± 4,413 | 742 ± 290 |
| Single global trajectory | 3,066 ± 2,996 | 466 ± 302 |
Notably, the asymmetric collapse between “global factories + separated units” (43,528) and “separated factories + global units” (3,573) confirms that unit-level credit carries the signal. Factory-level trajectory separation is nearly free to drop, unit-level separation is critical.
Optimal Number of Trajectories
We grouped units into groups based on modulo of their unique IDs. Ice throughput increased monotonically with : from 3,573 with a single group, to 14,388 (), 29,459 (), 32,049 (), 36,847 (), and 44,472 with fully separated trajectories, a 12.4× improvement from 1 group to full separation. The jump from 16 groups to fully separated yielded a further 20% gain, indicating that maximal decomposition best captured the diversity of individual agent behaviors.
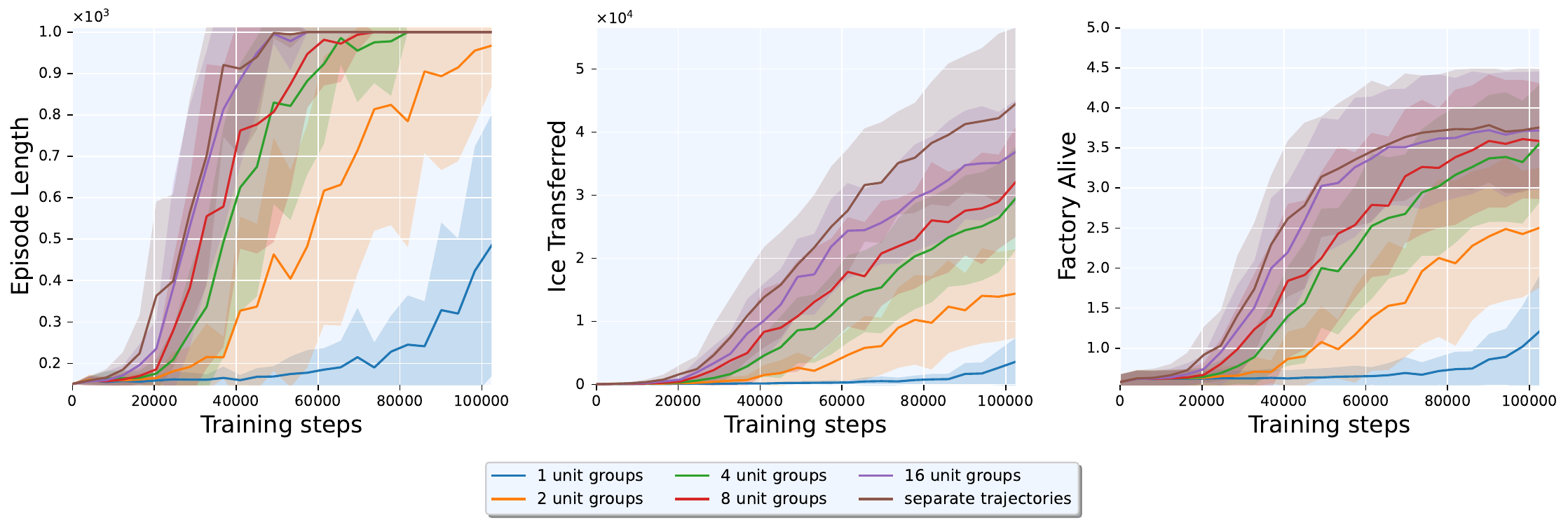
Trajectory Number Reduction through Grouping
While trajectory separation provided efficient training, it could lead to imbalanced mini-batches due to varying numbers of active trajectories per step. We tested bounded grouping rules: map quadrants (22,385 ice), closest factory (27,009), and closest heavy unit (35,224). The closest-heavy heuristic outperformed spatial groupings, suggesting behavioral similarity was a stronger grouping criterion than spatial proximity, yet all heuristics underperformed fully separated trajectories (44,472). Any grouping sacrificed credit assignment resolution.
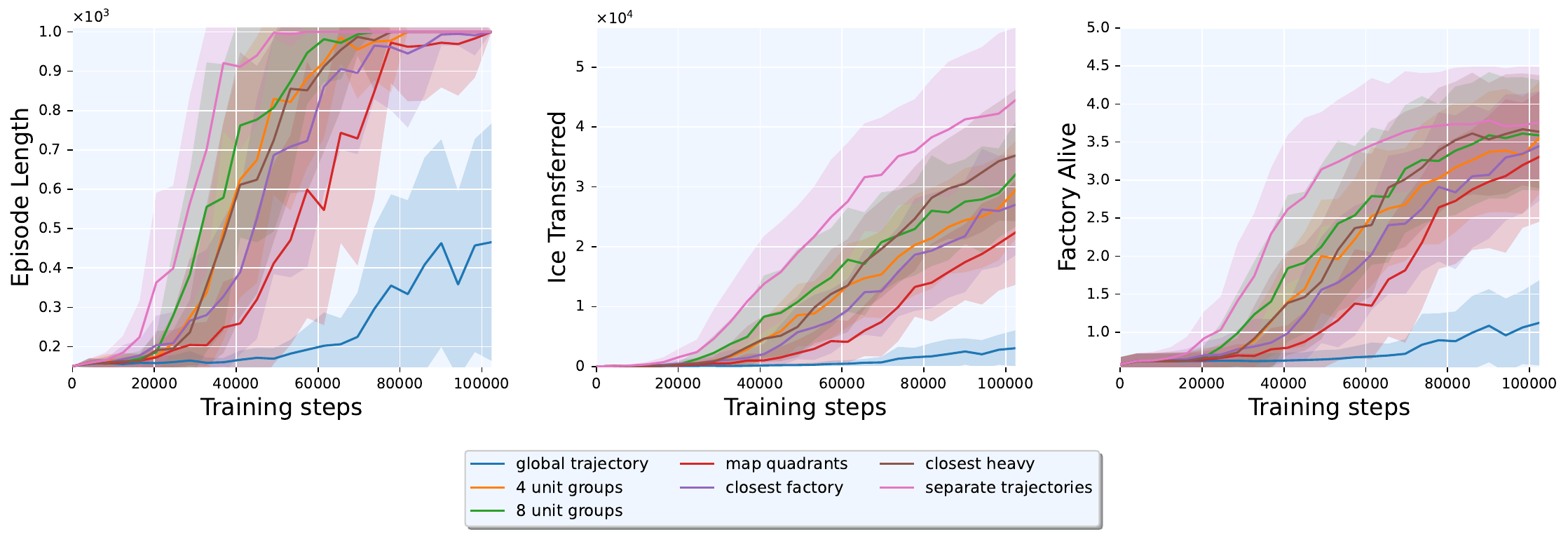
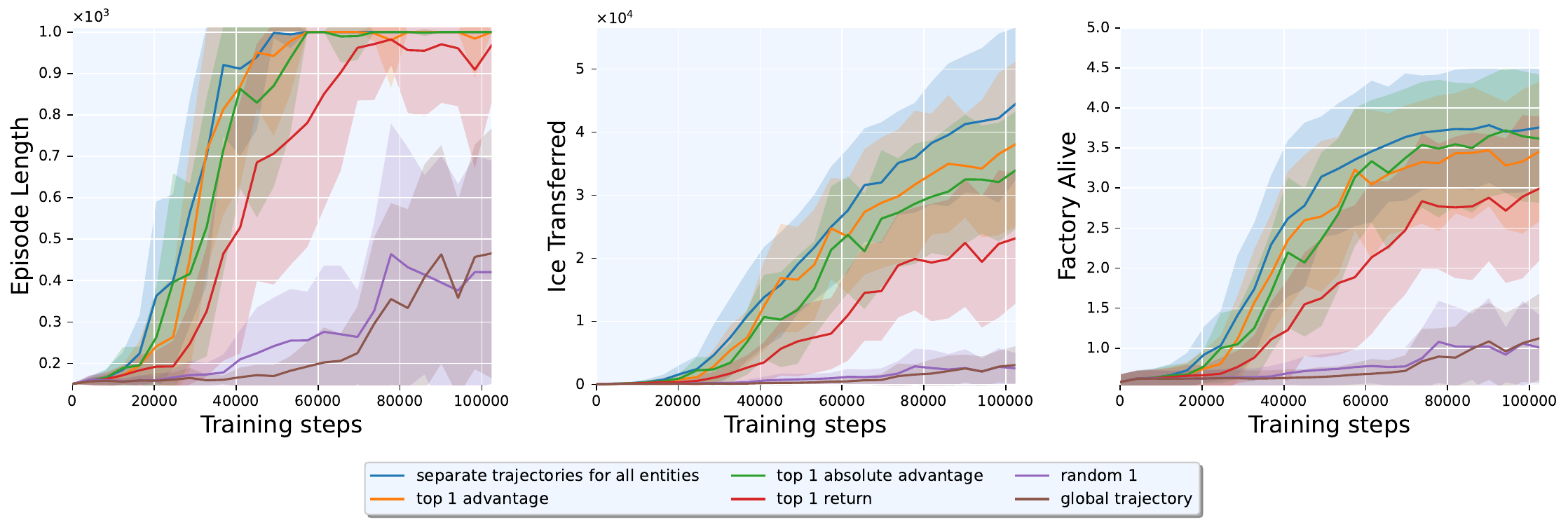
Train Sample Reduction
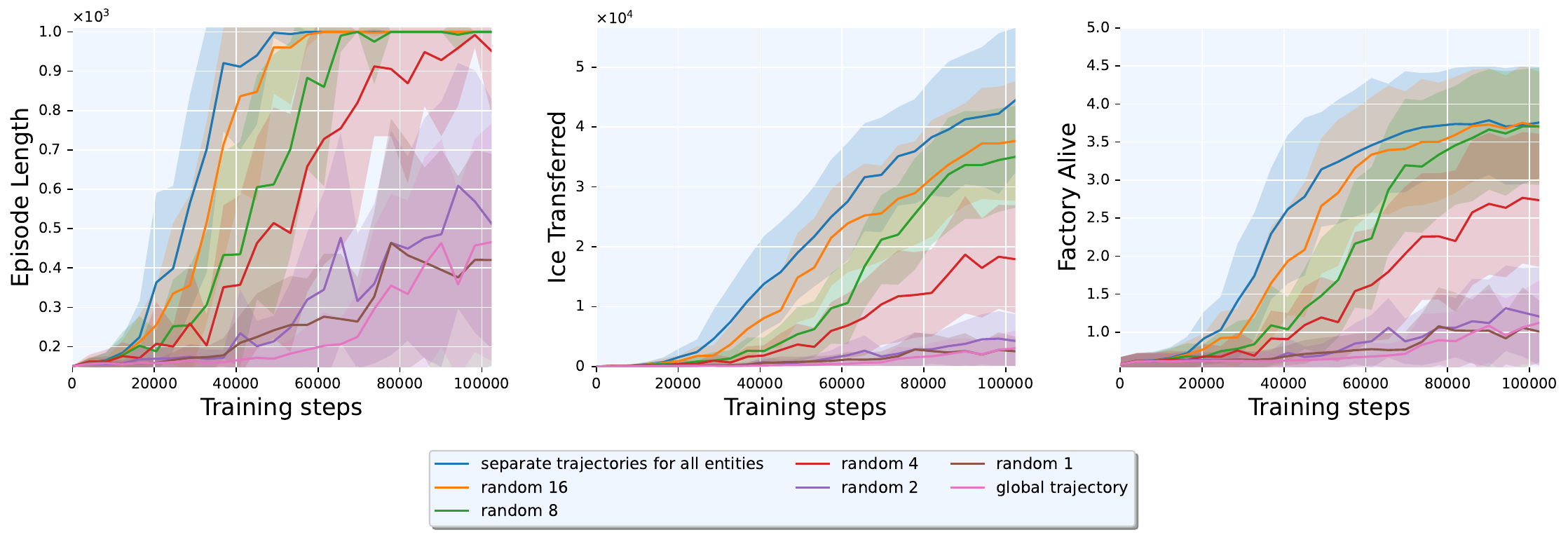
Given that all grouping methods underperformed full separation, we adopted training sample reduction, selecting the top training examples from each step. Selecting the single highest-advantage trajectory achieved 38,072 ice (86% of full separation), top absolute advantage reached 33,926, top return 23,156, and random selection only 2,550 (comparable to the global baseline at 3,066). This suggests data quality over data quantity: a single well-chosen training sample nearly matched using all samples.
We also investigated random sampling with different sample sizes (1, 2, 4, 8, 16). Performance improved with sample count, but sampling a single training example from an environment step with separate trajectories yielded the same suboptimal outcome as using a global trajectory, reinforcing that trajectory separation’s benefit came from the diversity of per-entity training signals rather than mere data augmentation.
Ablation: Which Components Matter?
Systematically removing separation components reveals their relative importance:
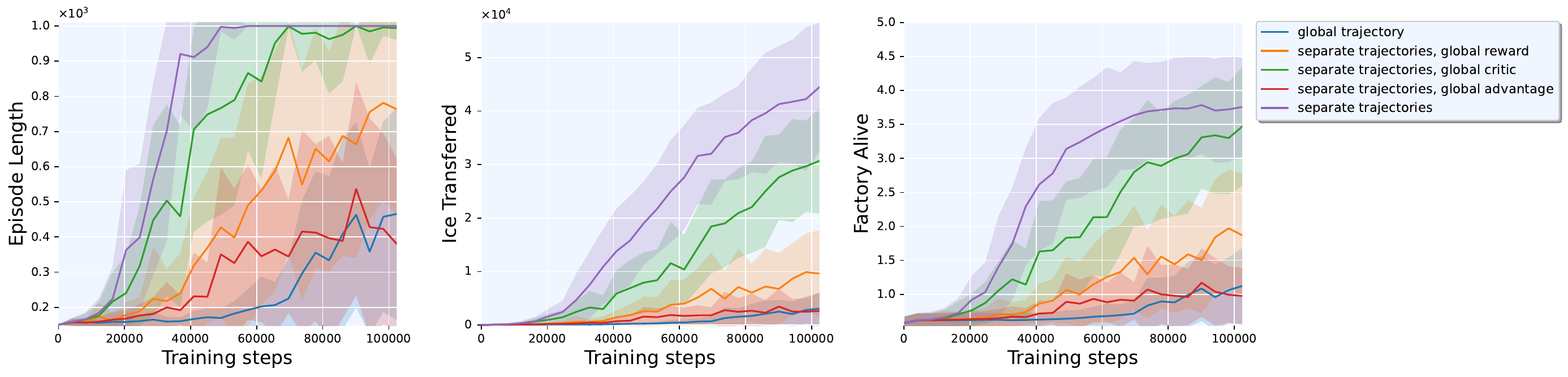
- Replacing per-entity rewards with a global reward dropped ice throughput by 78% (44,472 → 9,614), the most critical component.
- Replacing per-entity critics with a global critic still allowed convergence but reduced throughput by 31% (44,472 → 30,687).
- Eliminating both (global advantage) collapsed performance to 2,643 ice, below even the single global trajectory baseline (3,066), since a fully global advantage yields identical values for all entities.
Comparison with MAPPO and IPPO
We compared TS against MAPPO (centralized critic, team reward broadcast equally) and IPPO (independent critic, team reward broadcast equally). All three methods share the same network architecture and PPO hyperparameters, the only differences are in critic structure and reward assignment.
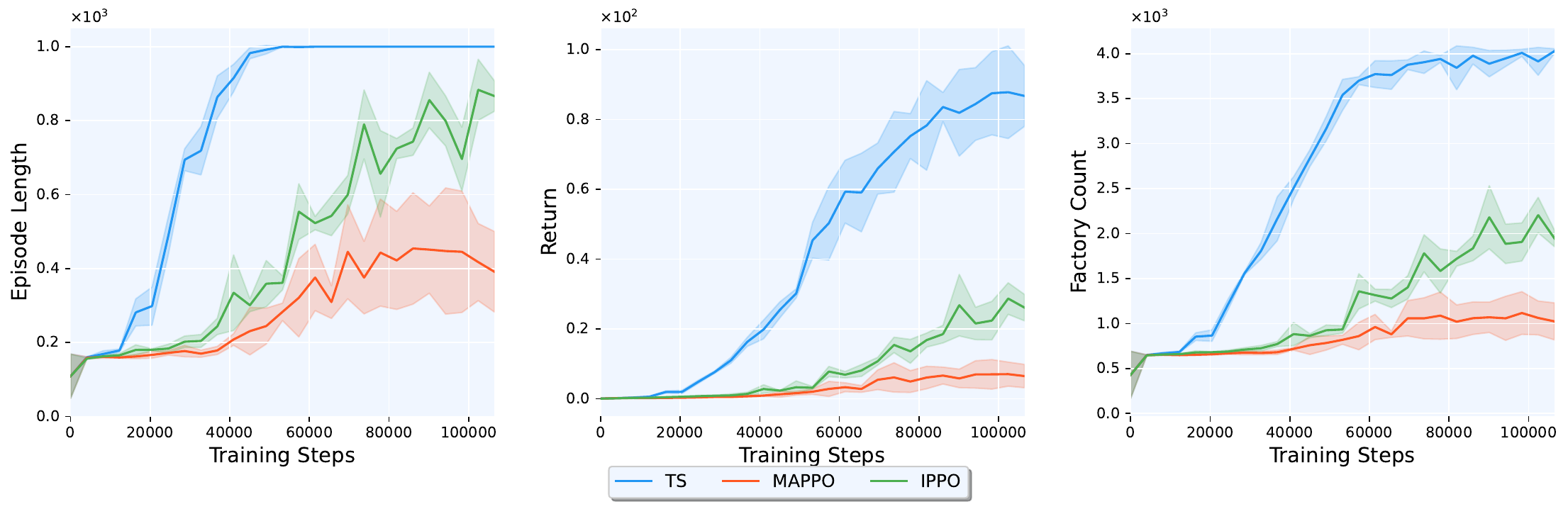
| Metric | TS (ours) | MAPPO | IPPO |
|---|---|---|---|
| Episode Length | 1,000.0 ± 0.0 | 391.1 ± 109.0 | 866.5 ± 41.0 |
| Return | 87.51 ± 8.78 | 6.33 ± 3.60 | 25.70 ± 4.76 |
| Factory Count | 4,028.7 ± 25.6 | 1,024.2 ± 206.0 | 1,946.3 ± 91.7 |
TS achieves a return of compared to IPPO’s and MAPPO’s , a 240% and 1,282% improvement respectively. Welch’s -tests and Cohen’s effect sizes confirm large statistical significance (, ), with the return metric yielding for TS vs. MAPPO and for TS vs. IPPO.
Comparison with Competition Solutions
We compared against top submissions from the 2023 NeurIPS Lux AI Competition, focusing on factory survival.
| Method | Params | Train Time | Env Steps |
|---|---|---|---|
| TS (ours) | 200K | 2 hours | 102K |
| Organizer baseline | 451K | 2 days | 1.4M |
| Best RL entry (FLG) | 6.08M | 2 days | 65M |
Our method achieves the target with only 200K parameters and 2 hours of training, compared to FLG’s 6.08M parameters and 2 days, and the organizer baseline’s 451K parameters and 2 days.
Conclusion
We presented a trajectory separation technique within a hybrid control framework that combines shared feature extractors with per-entity policy updates. In Lux AI, the method achieves the resource throughput of global-trajectory baselines and improves returns by 240% over IPPO and 1,282% over MAPPO, while using significantly fewer parameters and training steps than competition solutions.
A key limitation is that coordination in our framework emerges only through shared features, not explicit communication. In settings with sparse rewards or strong temporal dependencies, additional mechanisms such as causal influence modeling or tailored reward shaping may be required. More broadly, trajectory separation applies to any policy-gradient algorithm maintaining rollout buffers (e.g. TRPO, A3C). Future work will extend the approach to additional cooperative environments with varying team sizes, heterogeneous agent populations, partially observable settings, and explore adaptive blending of localized and centralized critics.
Citation
Read the full paper for more details: [Paper], and if you find this work informative please consider citing it:
@inproceedings{takacs2026trajectoryseparation,
author = {Tak\'acs, Tam\'as and Guly\'as, L\'aszl\'o and Magyar, Gergely},
title = {Trajectory Separation for Scalable Credit Assignment in Cooperative Multi-Agent Reinforcement Learning},
booktitle = {Proceedings of the International Conference on Computational Collective Intelligence (ICCCI)},
year = {2026},
publisher = {Springer},
series = {LNCS}
}back to papers