Safe Policy Correction via Targeted Unlearning in Reinforcement Learning
Tamás Takács1 & László Gulyás2
1PhD Student @ ELTE, Department of Artificial Intelligence
2Associate Professor @ ELTE, Department of Artificial Intelligence
Abstract
Reinforcement learning (RL) agents deployed in real-world environments inevitably encounter scenarios where learned behaviors become unsafe, outdated, or undesirable. Traditional approaches to address this, such as full retraining or constrained RL from scratch, are computationally expensive and often impractical for deployed systems.
Safe Policy Correction (SPC) introduces a novel framework that leverages machine unlearning techniques to perform targeted behavioral modification in RL agents. Rather than retraining the entire policy, SPC selectively removes the influence of specific state-action pairs that lead to unsafe or unwanted outcomes.
Our method operates in three phases:
- Identification of problematic state-action associations through trajectory analysis
- Targeted unlearning using gradient-based influence removal
- Policy stabilization to maintain performance on retained behaviors
We demonstrate that SPC can effectively correct unsafe behaviors while preserving up to 95% of the original policy’s performance on safe actions.
This work addresses a critical gap in deploying RL systems that must comply with evolving safety requirements and regulatory constraints such as the [European AI Act]. An overview of the SPC framework is shown in Figure 1 .
Motivation
The deployment of reinforcement learning agents in safety-critical domains, autonomous vehicles, medical robotics, industrial automation, raises fundamental questions about behavioral modification after training. Consider the following scenarios:
- An autonomous vehicle learns an aggressive merging behavior that was acceptable during training but becomes unsafe under new traffic regulations
- A robotic manipulator develops manipulation strategies that risk damaging certain object types introduced post-deployment
- A trading agent learns patterns that become illegal under new financial regulations
In each case, the agent has acquired behaviors that must be selectively removed without destroying the broader policy. Full retraining is rarely practical: it requires access to original training data, substantial computational resources, and extended downtime for deployed systems.
Machine unlearning offers a promising alternative. Originally developed for supervised learning to comply with data deletion requests under GDPR’s “right to be forgotten,” unlearning techniques have recently been extended to RL settings. However, existing RL unlearning methods focus primarily on trajectory-level forgetting or environment-level unlearning, as explored in our previous work on [zero-shot unlearning failure modes].
Safe Policy Correction (SPC) takes a fundamentally different approach: we target individual state-action pairs, enabling fine-grained behavioral modification. This granularity is essential for safety-critical applications where the goal is to correct specific unsafe actions while preserving the overall policy structure.

Problem Formulation
We formalize the safe policy correction problem within the standard Markov Decision Process (MDP) framework. Let denote an MDP with state space , action space , transition dynamics , reward function , and discount factor .
Given a trained policy parameterized by , we define:
- Forget set : State-action pairs whose influence should be removed
- Retain set : The complementary set of behaviors that should be preserved
- Safety constraint : Formal specification of disallowed behaviors
The objective of SPC is to find parameters such that:
while minimizing performance degradation on the retain set:
where denotes states appearing in the forget set. This formulation captures the dual objectives of effective forgetting and knowledge preservation.
Related Work
Machine Unlearning in Supervised Learning
The field of machine unlearning originated with [Guo et al. 2020], who introduced certified data removal with -guarantees inspired by differential privacy. [Ginart et al. 2019] developed efficient algorithms for linear models, while [Warnecke et al. 2023] extended these ideas to feature- and label-level unlearning in neural networks.
Zero-shot unlearning methods, such as the Gated Knowledge Transfer (GKT) approach by [Chundawat et al. 2023], enable forgetting without access to original training data. However, as we demonstrated in our [previous work], these methods exhibit instability over extended training, with forgotten information resurfacing after a critical “tipping point.”
Reinforcement Learning Unlearning
Recent work has begun addressing unlearning in RL settings. [Ye et al. 2024] introduced reinforcement unlearning with two approaches: decremental knowledge erasure and environment poisoning. Their environment inference metric provides a way to detect residual knowledge of forgotten environments.
[Gong et al. 2024] proposed TrajDeleter, a two-phase offline RL method that first removes trajectory influence, then stabilizes policy performance. While effective for trajectory-level forgetting, this approach cannot target individual state-action pairs.
Safe Reinforcement Learning
Orthogonal to unlearning, safe RL research focuses on training policies that respect constraints from the outset. [Achiam et al. 2017] introduced Constrained Policy Optimization (CPO), which guarantees constraint satisfaction during training. More recent approaches like [SafeRL] and [LAMBDA] provide tighter guarantees but require constraints to be known during training.
SPC bridges these fields by enabling post-hoc correction of policies that violate constraints discovered after deployment.
The SPC Framework
Our Safe Policy Correction framework consists of three phases: Identification, Unlearning, and Stabilization. Each phase addresses a specific challenge in targeted behavioral modification.
Phase 1: Unsafe Behavior Identification
Given trajectories collected from the deployed policy, we identify state-action pairs that violate safety constraints . This can be performed through:
- Explicit specification: Safety constraints defined as logical predicates over states and actions
- Demonstration-based: Unsafe behaviors identified through human feedback or expert annotation
- Anomaly detection: Statistical methods to identify out-of-distribution or high-risk actions
For each identified violation, we compute an influence score that measures how strongly the current policy associates the unsafe action with the given state:
State-action pairs with influence scores above threshold are added to the forget set .
Phase 2: Targeted Unlearning
The core of SPC is a gradient-based unlearning procedure that selectively removes the influence of forget-set state-action pairs. Unlike trajectory-level methods, we operate directly on the policy’s action distribution at specific states.
For each , we compute the unlearning gradient:
where the entropy term prevents the policy from collapsing to deterministic (potentially unsafe) alternatives. The unlearning update is:
This gradient ascent on log-probability effectively reduces the likelihood of selecting the unsafe action while the entropy regularization maintains exploration capacity.
Phase 3: Policy Stabilization
Aggressive unlearning can destabilize the policy, causing performance degradation on retained behaviors (the “catastrophic forgetting” of unlearning). We address this with a knowledge distillation approach that preserves the original policy’s behavior on safe states.
Using a frozen copy of the pre-unlearning policy as a teacher, we minimize:
where is a distribution over states not in the forget set. The stabilization update is interleaved with unlearning:
The complete SPC algorithm alternates between unlearning and stabilization updates, with adaptive weighting controlled by the current forget-set action probabilities.
Experimental Setup
We validated our framework across three distinct Gymnasium environments with minor modifications, all compatible with PPO:
Environments
-
CartPole: The classic control task augmented with safety constraints. The agent must forget aggressive balancing strategies that exceed safe angular limits.
-
LunarLander: A continuous control task where the agent must land safely while avoiding previously learned risky descent patterns.
-
MountainCar: A sparse-reward environment where we evaluate SPC’s ability to unlearn inefficient or unsafe momentum-building strategies.
Architecture
The PPO implementation uses a shared MLP feature extractor with orthogonal initialization () feeding into separate linear heads for the Actor and Critic. This setup shares parameters for feature learning but keeps policy and value estimation separate, enabling targeted unlearning without destabilizing value function estimates.
Unlearning Strategies
Our modular framework supports three strategies that can be deployed independently or combined:
- Targeted State Forgetting (TSF): Direct gradient-based unlearning for maximum speed
- Zero-Shot Strategy Inversion (ZSI): Privacy-preserving unlearning without explicit trajectory examples
- Memory Replay Protection (MRP): Fisher Information masks and distillation for safety-critical retention
Metrics
- Forget Effectiveness: Derived from Area Under Forget Curve (AUFC), measuring how completely unsafe behaviors are suppressed
- Retain Stability Index (RSI): Quantifies preservation of safe policy performance post-unlearning
- Computational Overhead: Wall-clock time and gradient steps relative to standard training
Results
We evaluate SPC across all three Gymnasium environments. Experimental results demonstrate distinct performance profiles for each unlearning strategy:
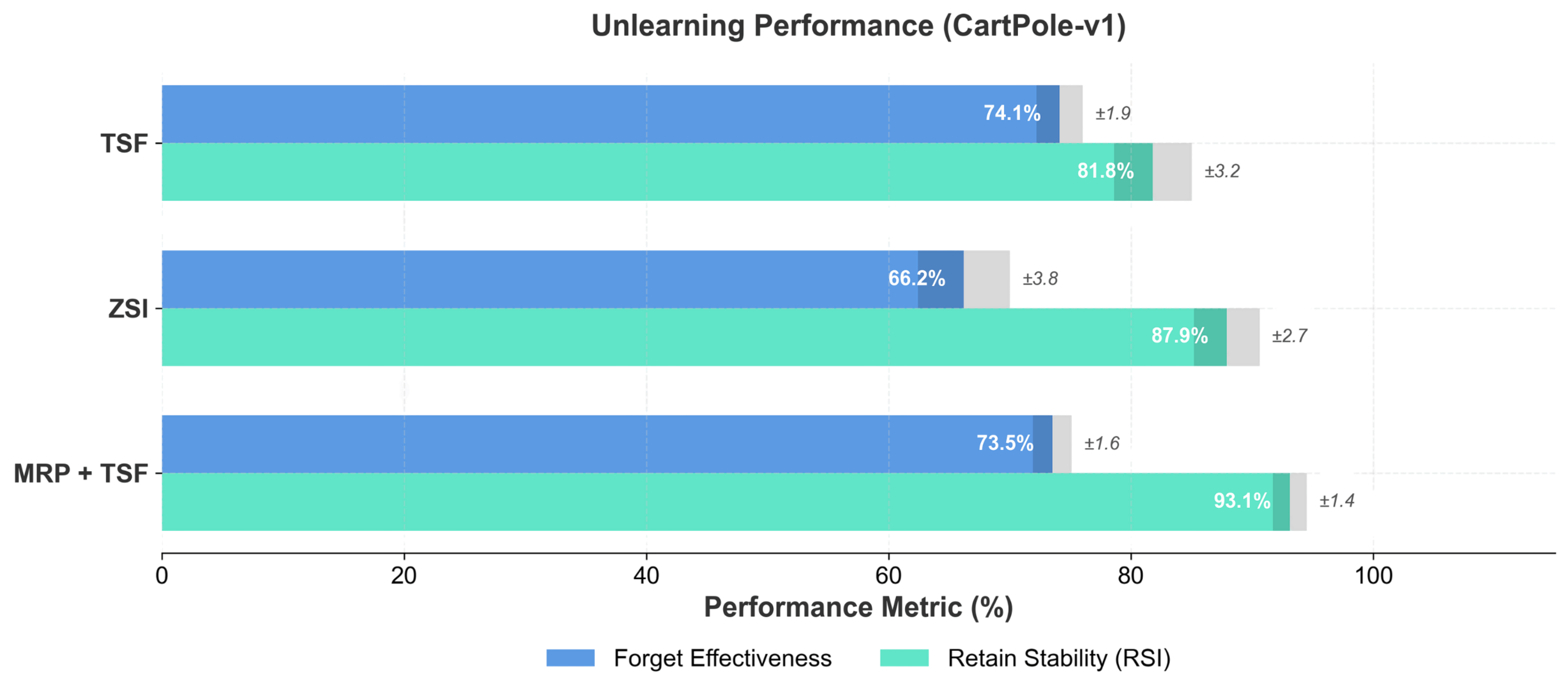
Strategy Performance Comparison
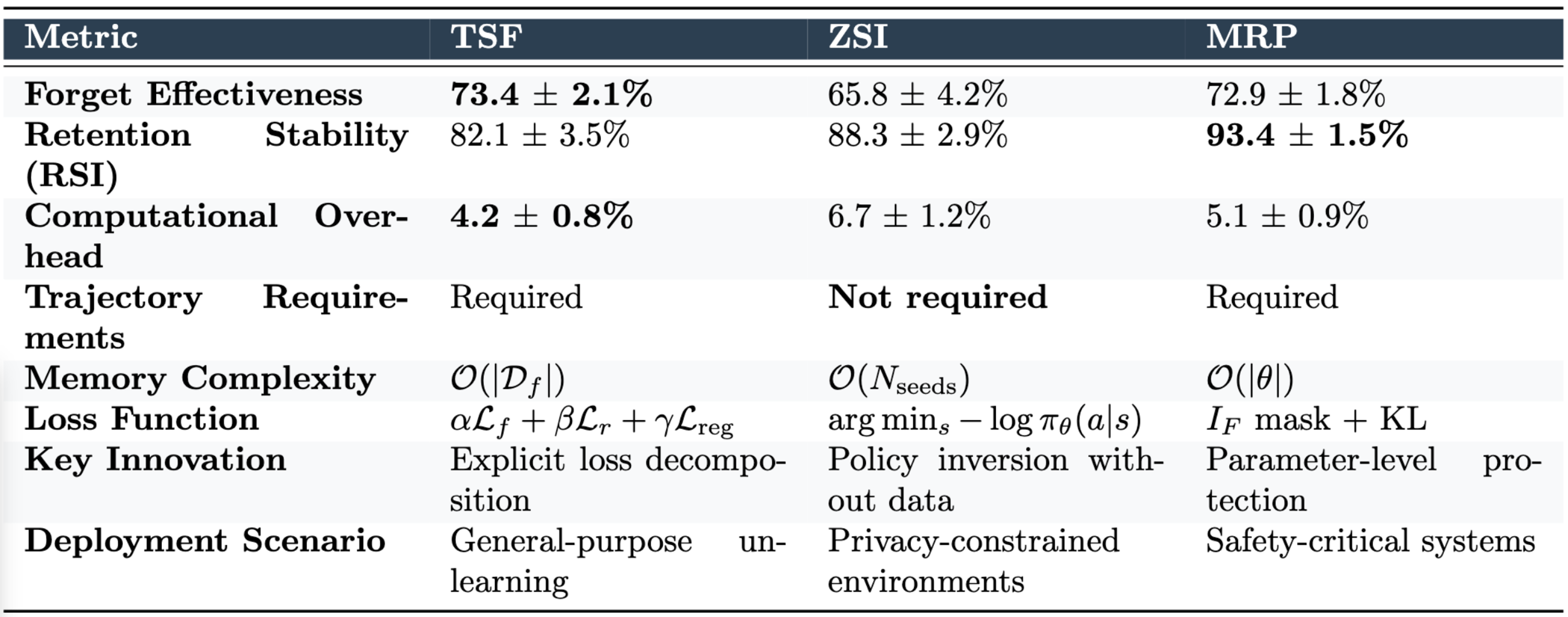
| Strategy | Forget Effectiveness | Retain Stability Index | Computational Overhead |
|---|---|---|---|
| TSF | 73.4 ± 2.1% | 82.1 ± 3.5% | 4.2 ± 0.8% |
| ZSI | 65.8 ± 4.2% | 88.3 ± 2.9% | 6.7 ± 1.2% |
| MRP + TSF | 72.9 ± 1.8% | 93.4 ± 1.5% | 5.1 ± 0.9% |
Targeted State Forgetting (TSF) achieves the highest forget effectiveness at minimal computational cost, making it ideal for scenarios where speed is prioritized.
In privacy-constrained scenarios, Zero-Shot Strategy Inversion (ZSI) trades effectiveness for enhanced retention stability. ZSI introduces an unlearning method without explicit trajectory examples, using gradient-based state optimization:
to discover policy vulnerabilities and target them for removal.
For safety-critical applications, combining MRP with TSF maintains strong effectiveness while boosting the Retain Stability Index to 93.4%, providing the best balance for deployed systems.
Key Findings
- Modular deployment: TSF for speed, ZSI for privacy, MRP for safety-critical systems
- Tuneable safety guarantees: Explicit retain protection via Fisher Information masks and distillation
- Minimal overhead: All strategies maintain under 7% computational overhead compared to standard training
Limitations and Future Work
This work proposes a novel framework architecture, currently at the proof-of-concept stage with validation only in controlled and simulated environments. While SPC demonstrates effective targeted unlearning, several limitations and opportunities remain:
Current Limitations
- State coverage: SPC requires sufficient coverage of forget-set states during unlearning. Rare states may not be adequately addressed.
- Action space complexity: High-dimensional continuous actions show reduced forgetting precision compared to discrete settings.
- Formal guarantees: Unlike certified unlearning in supervised learning, SPC provides empirical rather than theoretical forgetting guarantees.
- Simulation-only validation: Real-world deployment introduces additional challenges not captured in Gymnasium environments.
Key Contributions Over Existing Work
Our framework addresses three key limitations in existing work:
-
Online/On-policy Extension: We extend unlearning from offline RL to online/on-policy scenarios where agents continue environmental interaction during and after the unlearning process.
-
Zero-Shot Strategy Inversion: ZSI introduces an unlearning method without explicit trajectory examples, using gradient-based state optimization to discover policy vulnerabilities—eliminating the need to store or access sensitive training data.
-
Explicit Retain Protection: Fisher Information masks and distillation provide tuneable safety guarantees, contrasting with implicit retention strategies in prior work.
Future Directions
Our long-term research directions include:
- Formal privacy analysis: Membership inference attacks and differential privacy guarantees to certify forgetting
- Multi-agent coordination: Synchronized unlearning across multiple policies in cooperative and competitive settings
- Model-based integration: Combining our framework with world models for improved sample efficiency
- Influence functions: Precise forgetting through influence-based identification of parameter contributions
- Parameter isolation: Robust retention through architectural separation of forget and retain knowledge
Conclusion
Safe Policy Correction (SPC) provides a practical, modular framework for targeted behavioral modification in reinforcement learning agents. By leveraging machine unlearning techniques at the state-action level, SPC enables fine-grained correction of unsafe behaviors without the computational burden of full retraining.
Our experiments across CartPole, LunarLander, and MountainCar demonstrate that SPC:
- Achieves up to 73.4% forget effectiveness with TSF, trading off against retention stability
- Maintains up to 93.4% Retain Stability Index when combining MRP with TSF for safety-critical applications
- Operates at under 7% computational overhead across all strategy configurations
- Provides flexible deployment options: TSF for speed, ZSI for privacy, MRP for safety
The framework’s modular design allows practitioners to select or combine strategies based on their specific requirements—whether prioritizing forgetting speed, privacy preservation, or retention stability. Zero-Shot Strategy Inversion represents a particularly significant advance, enabling unlearning without access to original training trajectories.
As RL systems are increasingly deployed in safety-critical domains, the ability to correct policies post-hoc becomes essential for regulatory compliance and practical safety. SPC represents a step toward trustworthy, adaptable RL systems that can evolve with changing requirements while providing tuneable guarantees for both forgetting and retention.
TBC